Следвайте за актуализации и оферти
Получавайте известия за отстъпки, нови функции и промени в цените на vui
Подобни инструменти
David AI
Предлага подбрани аудио набори от данни за обучение на модели за разпознаване на реч и разговорен ИИ.
Otter
Автоматизира транскрипцията и обобщава основните точки по време на срещи и разговори.
Voicemod
Променете гласа си в реално време с различни ефекти за игри и живо предаване.
Fluently
AI-базиран английски учител за персонализирана практика на говор и мигновена обратна връзка.
NoteWave
Прехвърля и обобщава срещи в реално време, улавяйки ключови решения и действия.

vui Медийна галерия
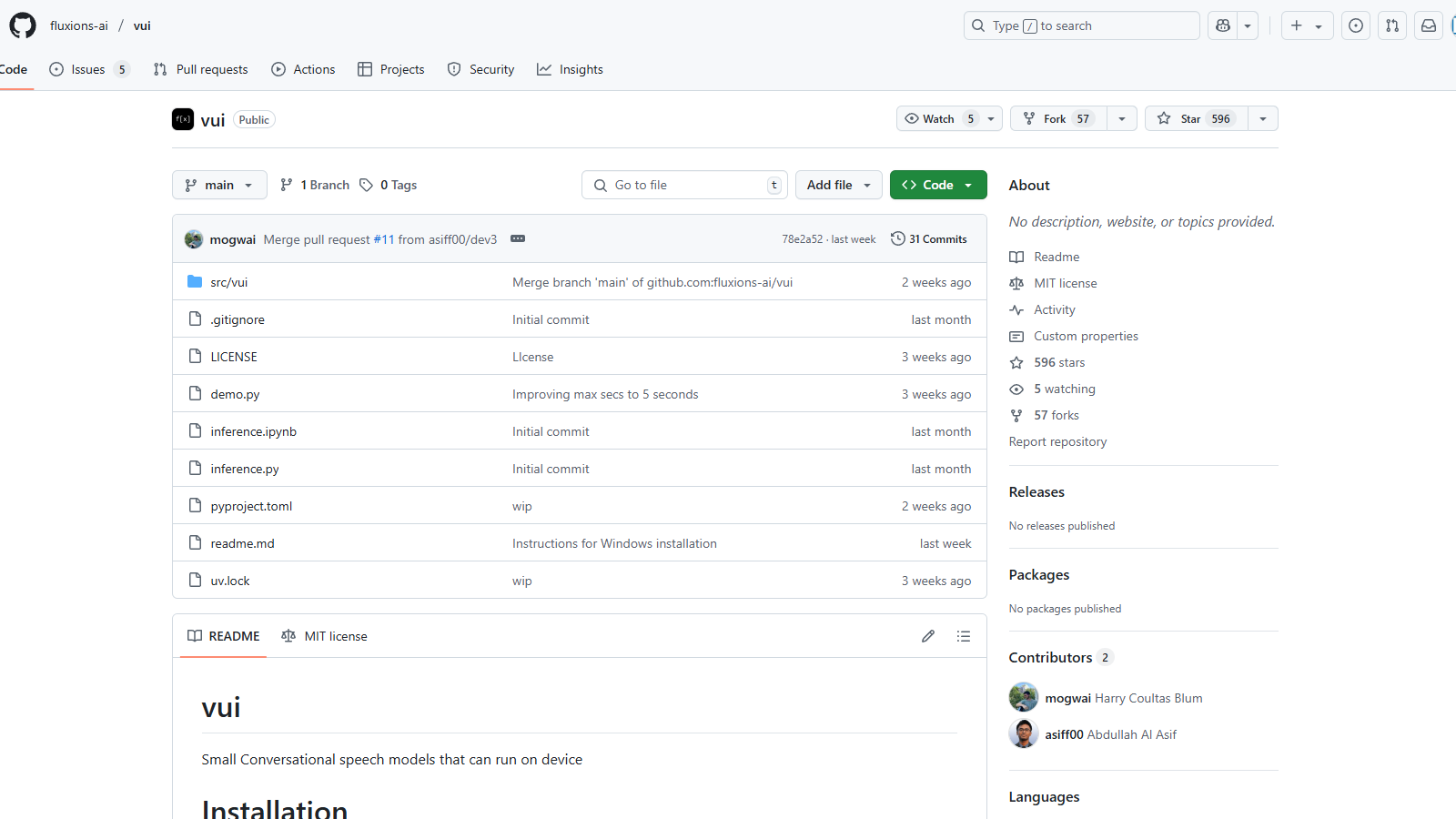
Какво е vui?
VUI е иновативен инструмент, фокусиран върху разговорни речеви модели, проектирани да работят директно на устройства, предоставяйки ефективно и удобно решение за задачи свързани с речта. Основните модели, налични в инструмента VUI, са обучени на обширни набори от данни, което им позволява да обработват аудио ефективно и да генерират контекстуално релевантни отговори.
Обновени ключови функции:
- Множество модели: Vui предлага разнообразие от модели, включително Vui.BASE, Vui.ABRAHAM и Vui.COHOST, всеки оптимизиран за различни типове разговорни взаимодействия. Vui.BASE е специално обучен на 40k часа аудио разговори, предоставяйки стабилна основа за различни приложения.
- Клониране на глас: Потребителите могат да използват моделите за възможности за клониране на глас, позволявайки им да репликират гласове с разумна точност на базата на предварително обучените набори от данни. Умението да се клонират гласове е подобрено, но е отбелязано, че резултатите може да не са перфектни поради ограничения в данните за обучение.
- Ефективност: Моделите са проектирани да функционират ефективно на устройства без необходимост от обширни облачни ресурси, което ги прави идеални за приложения, изискващи по-ниска латентност и висока реактивност. Моделите на VUI използват трансформатор, базиран на лама, който предсказва аудио токени, демонстрирайки напредък в архитектурата на модела, който подобрява тяхната оперативна ефективност.
- Аудио токенизация: Значителна функция е флуак аудио токенизаторът, който ефективно намалява броя на кодовете на секунда, подобрявайки общата скорост на обработка от 83.1hz на 21.53hz.
Инсталация и употреба:
За да започнат да използват VUI, потребителите могат лесно да го инсталират чрез мениджър на пакети с командата pip install -e .. Процесът на инсталация е очевиден, а демонстрация може да се стартира, като се изпълни python demo.py. Тази гъвкавост позволява на разработчиците да внедряват моделите в различни приложения, подобрявайки потребителските преживявания с безшевна функция за разпознаване и генериране на реч.
Предизвикателства и съображения:
Въпреки че моделите демонстрират впечатляващи възможности, те не са без ограничения. Потребителите могат да изпитат някои особености, като случайни халюцинации, които се появяват, когато AI генерира отговори, които не се основават на данни от обучението си. Тази реалност е признавана от екипа за разработка, докато те се стремят към непрекъснато подобрение и ангажираност с общността.
Въпреки тези предизвикателства, моделите VUI представляват значителен напредък в разговорния AI, особено за проекти, целящи да подобрят интерактивността чрез глас. Екипът за разработка подчертава непрекъснатото подобрение, споделянето на прозорци и адресирането на проблеми на базата на обратна връзка от общността. Този ангажимент за развитие е подкрепен от използването на авангардни технологии и съвместни усилия с други проекти с отворен код.
Приноси:
Развитието на VUI признава приноса на няколко проекта с отворен код, включително Whisper от OpenAI и Audiocraft от Facebook Research, демонстрирайки общо усилие за изграждане на стабилни инструменти за обработка на реч. Чрез тези сътрудничества, VUI подобрява своите предложения и запазва значимостта си в бързо развиващата се област на технологията за обработка на аудио.
Плюсове и минуси
Плюсове
- Предлага малки модели за разговорна реч, които могат да работят на устройството без нужда от облачна поддръжка.
- Включва модели за един говорител и за двама говорители, чувствителни към контекста, за разнообразни приложения.
- Използва трансформатор на база лама за предсказване на аудио токени, подобрявайки производителността.
Минуси
- Клонирането на глас не е перфектно поради ограничени данни за обучение и ресурси.
Често задавани въпроси
vui е с отворен код и е безплатен за използване.
Според нашата последна информация, този инструмент в момента не изглежда да има ограничена оферта, за съжаление.
{toolName} предлага три основни модела: Vui.BASE, който е базовият чекпойнт, обучен на 40k часа аудио разговори; Vui.ABRAHAM, проектиран като модел с един говорител, способен на отговори, осъзнаващи контекста, и Vui.COHOST, който позволява комуникация между двама говорители. Тези модели обслужват различни случаи на употреба, вариращи от основни разговорни взаимодействия до сложни диалози между множество страни.
Да, можете да стартирате {toolName} локално. За да го инсталирате, използвайте командата pip с следния синтаксис: 'pip install -e .'. Това ще инсталира инструмента в режим на редактиране. Убедете се, че имате инсталиран Python на устройството си за настройката. Следвайте документацията в README файла в репозитория за подробни стъпки и изисквания.
{toolName} предлага възможности за клониране на глас, но е важно да се отбележи, че основният модел може да не произвежда перфектни резултати поради ограничен набор от обучителни данни. Моделът не е получил обширни аудио входове, което води до несъответствия при клонирането на конкретни гласове. Потребителите трябва да управляват очакванията си и да имат предвид този аспект при използването на функцията за клониране на глас.
{toolName} използва здрава техника за токенизация на аудио, разработена в сътрудничество с Fluac, което е основано на Descript-Audio-Codec. Това значително намалява броя на обработваните аудио кодове, спадайки от 83.1 Hz до 21.53 Hz, което позволява по-ефективно управление на данните по време на обработка на аудио. Това подобрение позволява по-бързи и по-точни предсказания на гласа.
За оптимална производителност, {toolName} е най-добре да се използва на високопроизводително оборудване, в частност настройки с NVIDIA 4090 GPU, както е посочено от разработчика. Използването на такова мощно оборудване намалява времето за обработка и повишава способността на модела да обработва интензивни аудио операции.
Да, {toolName} наистина изпитва халюцинации, при които изходът може да не съвпада с реалността. Това е често срещан проблем в производителността на AI моделите, особено при обучение с ограничени ресурси. Потребителите трябва да бъдат наясно с това и да проверяват точността на критичните изходи.
Интегрирането на {toolName} с други инструменти, като Whisper и Audiocraft, може да разшири възможностите му. Whisper помага за надеждно разпознаване на реч, докато Audiocraft може да подобри функциите за обработка на звук. Изследването на тези партньорства може значително да повиши потребителското изживяване и функционалността на {toolName}.
{toolName} е хостван в GitHub, където потребителите могат да намерят общностна поддръжка чрез проблеми и дискусии. За подробни указания за употреба потребителите трябва да се запознаят с документацията README, предоставена в хранилището. Взаимодействието с общността също може да донесе полезни съвети за решаване на проблеми и прозрения от други потребители.