Voicebox
Lokales Sprachsynthese-Studio, das Sprachklonung und fortschrittliche Bearbeitungswerkzeuge für den professionellen Einsatz bietet.
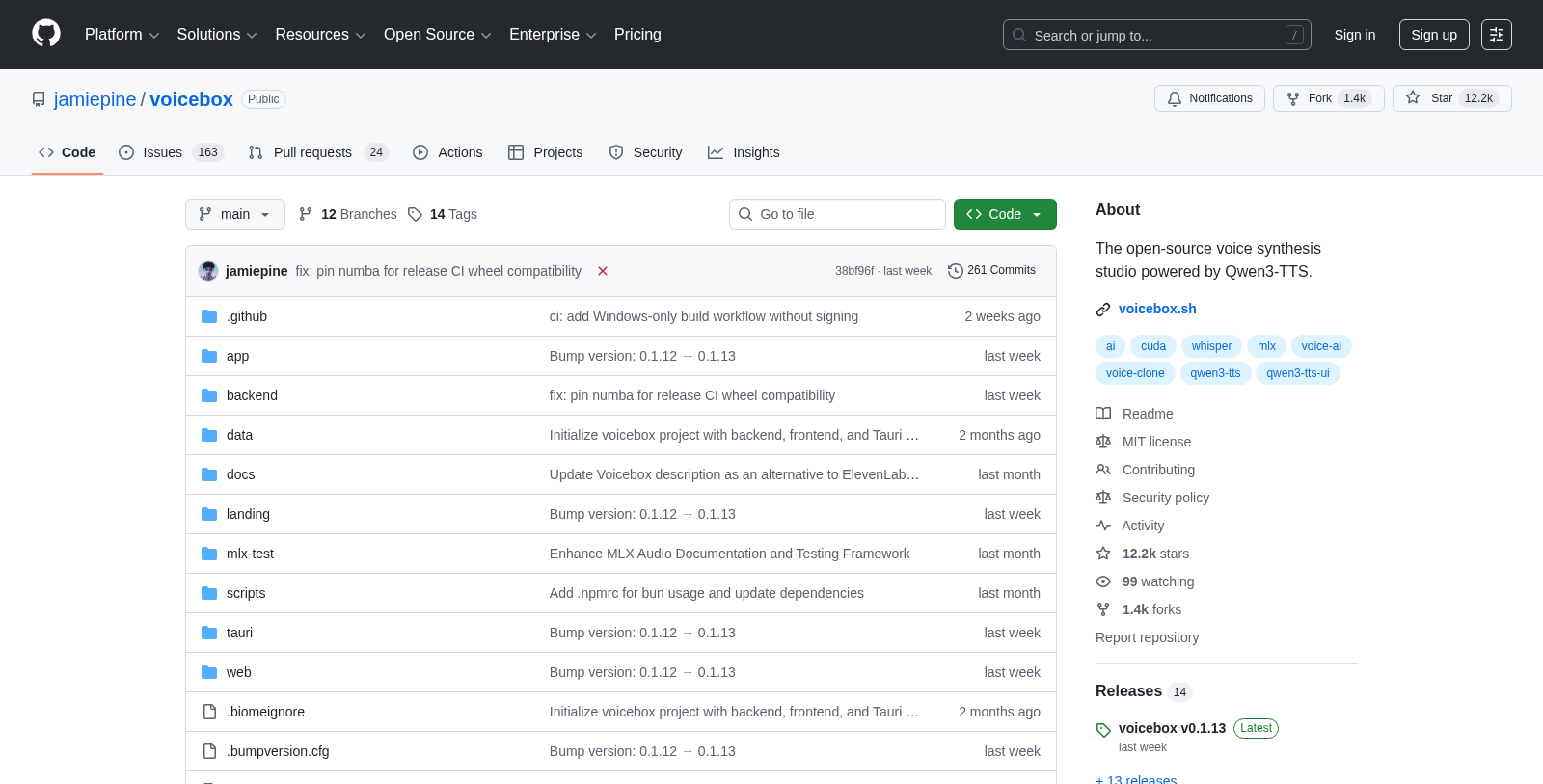
Github.com
Ist das Ihr Tool?
Folgen für Updates & Angebote
Erhalten Sie Benachrichtigungen für Voicebox Rabatte, neue Features & Preisänderungen
Ähnliche Tools
Bland AI
Automatisieren Sie eingehende und ausgehende Telefonanrufe mit mehrsprachigen KI-Agenten für die Unternehmenskommunikation.
Speechify
Konvertieren Sie Text in natürlich klingende Audioinhalte in mehreren Sprachen und Stimmen.
Resemble AI
Erstellen Sie lebensechte, KI-generierte Stimmen und erkennen Sie Deepfakes, um die Authentizität von Inhalten sicherzustellen.
Fluently
KI-gestützter Englisch-Tutor für personalisiertes Sprechtraining und sofortiges Feedback.
Amazon Bedrock AgentCore
KI-Agenten sicher und in großem Maßstab bereitstellen und betreiben.

Voicebox Medien-Galerie
Was ist Voicebox?
Voicebox ist ein lokal-orientiertes Sprachklon-Studio, das für die professionelle Sprachsynthese konzipiert wurde und über DAW-ähnliche Funktionen für nahtlose Sprachgenerierung und -bearbeitung verfügt. Als kostenlose und Open-Source-Alternative zu cloudbasierten Diensten wie ElevenLabs ermöglicht es Benutzer*innen, Stimmen zu klonen und Sprache vollständig auf ihren eigenen Maschinen zu generieren, wodurch sie vollständige Kontrolle und Privatsphäre über ihre Sprachdaten haben.
Eine der herausragenden Funktionen von Voicebox ist das Engagement für Privatsphäre. Im Gegensatz zu Cloud-Lösungen, die den Zugang und die Kontrolle der Nutzer*innen durch Abonnements einschränken können, ermöglicht Voicebox den Nutzer*innen, in einer lokalen Umgebung zu arbeiten, in der alle Modelle und Sprachdaten privat bleiben. Diese lokale Verarbeitung verbessert nicht nur die Sicherheit, sondern optimiert auch die Leistung, dank der nativen Tauri-Architektur.
Funktionen von Voicebox
Voicebox ist vollgepackt mit professionellen Werkzeugen und Funktionen, die umfassende Sprachklonung und -synthese ermöglichen. Die Sprachklon-Funktion wird durch das branchenbekannte Qwen3-TTS unterstützt, das die sofortige Sprachklonung aus nur wenigen Sekunden Audio ermöglicht. Diese Funktion unterstützt hohe Klangtreue und fängt den natürlichen Ton, die Tonhöhe und die emotionalen Nuancen der Stimmen ein. Mehrsprachige Unterstützung ist ebenfalls verfügbar, derzeit mit Englisch und Chinesisch, weitere Sprachen werden bald erwartet.
Erweiterte Bearbeitungswerkzeuge
Voicebox enthält auch fortschrittliche Bearbeitungsfunktionen, wie einen Multi-Track-Zeitlinien-Editor zum Erstellen komplexer Audio-Projekte. Nutzer*innen können nahtlos mehrere Sprachspuren zuschneiden, mischen und manipulieren, was Kreativität und effizientes Projektmanagement fördert. Das System unterstützt Inline-Bearbeitung, sodass Nutzer*innen Audio-Clips direkt in der Zeitlinie teilen und anpassen können, um einen intuitiveren Arbeitsablauf zu ermöglichen.
Aufnahmefunktionen sind in die Plattform integriert, die eine Aufnahme innerhalb der App mit Echtzeit-Wellenformvisualisierung ermöglicht. Zudem wird die Aufnahme von Systemaudio unterstützt, sodass Nutzer*innen alles aufzeichnen können, was auf ihrem Desktop abgespielt wird. Automatische Transkriptionsfunktionen, die von Whisper betrieben werden, steigern ebenfalls die Produktivität, indem sie gesprochene Worte effizient in Text umwandeln.
API-Integration
Für Entwickler*innen bietet Voicebox eine umfassende REST-API, die eine einfache Integration von Sprachsynthesefunktionen in bestehende Anwendungen oder neue Projekte erleichtert. Die API ermöglicht Automatisierung und programmatische Kontrolle über die Sprachgenerierung, wodurch Voicebox eine vielseitige Wahl für Entwickler*innen ist, die Sprachtechnologie in ihre Lösungen integrieren möchten.
Bereitstellungsoptionen
Voicebox schränkt Nutzer*innen nicht in eine Cloud-Infrastruktur ein, sondern bietet zwei Bereitstellungsoptionen: einen lokalen Modus, in dem alles direkt auf der Maschine läuft, und einen Remote-Modus, in dem Nutzer*innen eine GPU-Serververbindung in ihrem Netzwerk herstellen können. Diese Flexibilität ermöglicht es den Nutzer*innen, das beste Setup für ihre Betriebsbedürfnisse auszuwählen.
Zukünftige Verbesserungen
Voicebox hat sich verpflichtet, seine Fähigkeiten auszubauen, mit aufregenden Funktionen, die für zukünftige Releases in Planung sind. Dazu gehören Echtzeitsynthese für Streaming-Audio-Generierung, verbesserte Stimmeffekte wie Tonhöhenschwankungen und Hall sowie ein fortschrittlicherer Zeitlinien-Editor mit Wort-für-Wort-Präzisionsbearbeitung. Voicebox strebt an, eine All-in-One-Lösung für Sprachsynthese zu sein, einschließlich neuer Mechanismen zur Stimmenerstellung und einer mobilen Begleit-App für einfachere Steuerung unterwegs.
Mit seinem reichen Funktionsumfang zielt Voicebox darauf ab, die Art und Weise zu verändern, wie Nutzer*innen mit Sprachtechnologie interagieren, und Innovationen in Bereichen wie Spiel-Dialogsystemen, Podcast-Produktion, Barrierefreiheitswerkzeugen und automatisierter Inhaltsgenerierung voranzutreiben.
Vorteile & Nachteile
Vorteile
- Arbeitet vollständig auf lokalen Maschinen und gewährleistet somit die Privatsphäre und Sicherheit der Benutzerdaten.
- Verfügt über einen Mehrspur-Zeitachsen-Editor für fortgeschrittene Audio-Bearbeitung und Mixing.
- Unterstützt mehrere Sprachmodelle und Sprachen, was die Vielseitigkeit der Sprachsynthese erhöht.
Nachteile
- Derzeit fehlen Linux-Bausteine aufgrund von Einschränkungen des Speicherplatzes des GitHub-Runners.
Häufig gestellte Fragen
Voicebox ist Open Source und kostenlos zu nutzen.
Laut unseren neuesten Informationen scheint dieses Tool derzeit leider kein lebenslanges Angebot zu haben.
Voicebox bietet mehrere Funktionen, die für die Sprachmanipulation und -synthese konzipiert sind. Zu den wichtigsten Funktionen gehören die hochqualitative Sprachgenerierung, Spracherkennung (speech-to-text) und anpassbare Sprachparameter. Nutzer können realistische Sprach-Ausgaben für verschiedene Anwendungen generieren, wie Podcasts, Hörbücher und andere Medieninhalte, was es zu einem wertvollen Werkzeug für Content-Ersteller macht, die ihre Projekte mit Sprachübertragungen bereichern möchten.
Um mit Voicebox zu beginnen, besuchen Sie zuerst das offizielle GitHub-Repository. Klonen Sie das Repository auf Ihren lokalen Computer und folgen Sie den Installationsanweisungen, die in der Dokumentation bereitgestellt werden. Stellen Sie sicher, dass Sie die erforderlichen Abhängigkeiten installiert haben. Sobald alles eingerichtet ist, können Sie mit den bereitgestellten Beispielen experimentieren, um sich mit den Sprachsynthesefunktionen vertraut zu machen.
Voicebox erfordert ein kompatibles Betriebssystem und muss bestimmte Software-Abhängigkeiten erfüllen, um eine optimale Leistung zu gewährleisten. Normalerweise benötigen Sie ein System mit installiertem Python, zusammen mit spezifischen Bibliotheken, die in der Dokumentation erwähnt werden. Für das beste Erlebnis stellen Sie sicher, dass Ihre Umgebung die Funktionen zur Audiobearbeitung unterstützt, was möglicherweise zusätzliche Tools oder Bibliotheken erfordert.
Voicebox wurde für Flexibilität entwickelt und kann mit verschiedenen Softwareanwendungen integriert werden, insbesondere mit solchen, die Sprachsynthese oder -manipulation erfordern. Für spezifische Integrationsmöglichkeiten können Benutzer die Dokumentation oder Diskussionen in der Community auf GitHub konsultieren. Es wird empfohlen, bestehende Plugins oder API-Verbindungen zu erkunden, wenn Sie Voicebox mit anderen Tools verbinden möchten.
Obwohl Voicebox leistungsstark ist, gibt es potenzielle Einschränkungen, die zu beachten sind. Die Qualität der Sprachausgabe kann je nach Eingabe und verwendeten Einstellungen variieren, und die Verarbeitungszeit kann für hochqualitative Ausgaben erheblich sein. Außerdem ist die Auswahl an verfügbaren Stimmen im Vergleich zu kommerziellen Angeboten möglicherweise begrenzt, sodass die Benutzer ihre spezifischen Anwendungsfälle unter Berücksichtigung dieser Faktoren bewerten sollten.
Voicebox-Nutzer können Unterstützung über das GitHub-Repository finden, wo sie Probleme melden, Fragen stellen und Hilfe von der Gemeinschaft erhalten können. Die README-Datei des Projekts enthält oft FAQs und Tipps zur Fehlerbehebung. Nutzer sind eingeladen, an Diskussionen teilzunehmen und zur Gemeinschaft beizutragen, um gemeinsam zu lernen und Probleme zu lösen.
Voicebox konzentriert sich hauptsächlich auf vorab aufgezeichnete oder generierte Sprachausgaben und nicht auf die Sprachsynthese in Echtzeit. Nutzer, die an Echtzeitanwendungen interessiert sind, sollten möglicherweise andere Tools oder Frameworks erkunden, die sich auf die Live-Verarbeitung spezialisiert haben. Nichtsdestotrotz kann Voicebox kreativ in verschiedenen Kontexten eingesetzt werden, auch wenn es nicht für die Echtzeitanwendung entwickelt wurde.
Voicebox ist besonders nützlich für Content-Ersteller, Pädagogen und Entwickler. Zu den gängigen Anwendungsfällen gehören das Erstellen von Sprachaufnahmen für Videos, das Erstellen von Hörbüchern, die Entwicklung interaktiver Sprachanwendungen und die Synthese von Stimmen für Barrierefreiheitstools. Seine Vielseitigkeit ermöglicht zahlreiche Anwendungen, bei denen die Sprachgenerierung das Nutzererlebnis oder die Engagement verbessert.