Suivez pour des mises à jour et des offres
Recevez des alertes pour les réductions, les nouvelles fonctionnalités et les changements de prix de vui
Outils Similaires
David AI
Fournit des ensembles de données audio sélectionnées pour l'entraînement de modèles d'IA vocale et conversationnelle.
Fluently
Tuteur d'anglais alimenté par l'IA pour une pratique de la parole personnalisée et des retours instantanés.
Synthesia
Transformez du texte en vidéos générées par IA engageantes dans plus de 140 langues sans production étendue.
Candy AI
Interagissez avec des compagnons IA personnalisables par chat, voix et vidéo pour des interactions personnelles.
MetaVoice
Système vocal alimenté par l'IA permettant des conversations naturelles et émotionnellement conscientes sans échange traditionnel des tours de parole.

Galerie multimédia de vui
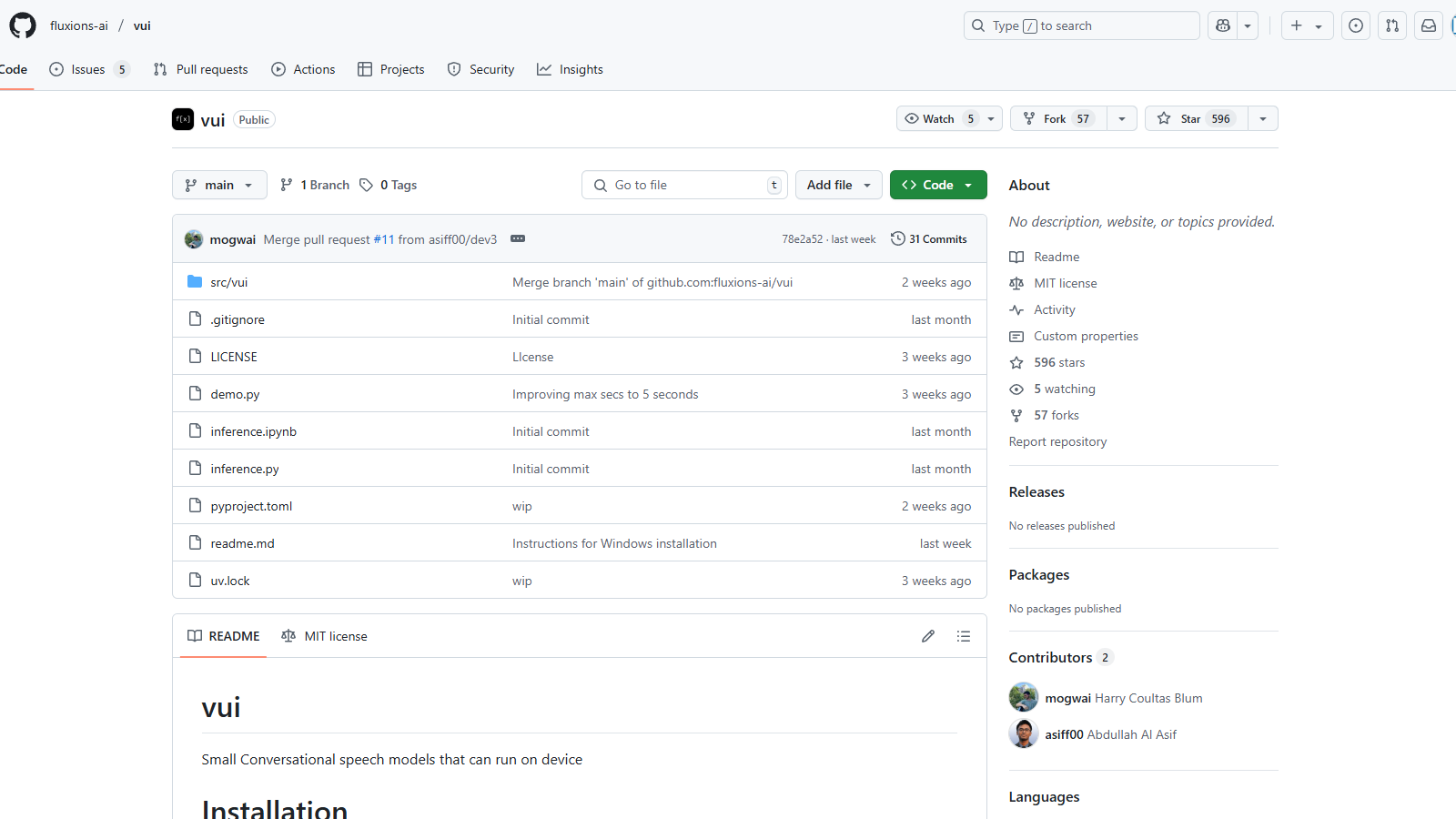
Qu'est-ce que vui ?
VUI est un outil innovant axé sur les modèles de discours conversationnels conçus pour fonctionner directement sur les appareils, offrant une solution efficace et conviviale pour les tâches liées à la parole. Les modèles principaux disponibles dans l'outil VUI sont formés sur de vastes ensembles de données, leur permettant de traiter l'audio efficacement et de produire des réponses contextuellement pertinentes.
Fonctionnalités Clés Mise à Jour :
- Multiple Modèles : Vui propose une variété de modèles incluant Vui.BASE, Vui.ABRAHAM, et Vui.COHOST, chacun optimisé pour différents types d'interactions conversationnelles. Vui.BASE a été spécifiquement formé sur 40k heures de conversations audio, offrant une base robuste pour diverses applications.
- Clonage Vocal : Les utilisateurs peuvent tirer parti des modèles pour des capacités de clonage vocal, leur permettant de répliquer des voix avec une précision raisonnable basée sur les ensembles de données pré-entraînés. La capacité à cloner des voix est améliorée, mais il est noté que les résultats peuvent ne pas être parfaits en raison des limitations des données d'entraînement.
- Efficacité : Les modèles sont conçus pour fonctionner efficacement sur des appareils sans avoir besoin de ressources cloud étendues, les rendant idéaux pour les applications nécessitant une faible latence et une haute réactivité. Les modèles VUI utilisent un transformateur basé sur un llama qui prédit des jetons audio, mettant en avant des avancées dans l'architecture des modèles qui améliorent leur efficacité opérationnelle.
- Tokenisation Audio : Une caractéristique significative est le tokenizeur audio fluac, qui réduit efficacement le nombre de codes par seconde, améliorant la vitesse de traitement globale de 83.1hz à 21.53hz.
Installation et Utilisation :
Pour commencer à utiliser VUI, les utilisateurs peuvent facilement l'installer via un gestionnaire de paquets en utilisant la commande pip install -e .. Le processus d'installation est simple, et une démo peut être exécutée en lançant python demo.py. Cette flexibilité permet aux développeurs d'implémenter les modèles dans diverses applications, améliorant l'expérience utilisateur avec des fonctionnalités de reconnaissance et de génération de la parole sans couture.
Défis et Considérations :
Bien que les modèles montrent des capacités impressionnantes, ils ne sont pas sans limitations. Les utilisateurs peuvent rencontrer certaines anomalies, comme des hallucinations occasionnelles, qui se produisent lorsque l'IA génère des réponses qui ne sont pas basées sur ses données d'entraînement. Cette réalité est reconnue par l'équipe de développement alors qu'elle s'efforce d'une amélioration continue et d'un engagement communautaire.
Malgré ces défis, les modèles VUI représentent une avancée significative dans l'IA conversationnelle, en particulier pour les projets visant à améliorer l'interactivité par la voix. L'équipe de développement met l'accent sur l'amélioration continue, le partage d'idées et la résolution de problèmes basés sur les retours de la communauté. Cet engagement envers le développement est soutenu par l'utilisation de technologies de pointe et des efforts collaboratifs avec d'autres projets open-source.
Attributions :
Le développement de VUI reconnaît les contributions de plusieurs projets open-source, y compris Whisper par OpenAI et Audiocraft par Facebook Research, mettant en avant un effort communal vers la construction d'outils robustes pour le traitement de la parole. Grâce à ces collaborations, VUI améliore ses offres et maintient sa pertinence dans le domaine en rapide évolution de la technologie de traitement audio.
Avantages & Inconvénients
Avantages
- Offre de petits modèles de parole conversationnelle pouvant fonctionner sur l'appareil sans nécessiter de support cloud.
- Comprend des modèles à un seul locuteur et à double locuteur sensibles au contexte pour des applications polyvalentes.
- Utilise un transformateur basé sur un lama pour la prédiction de tokens audio, améliorant ainsi la performance.
Inconvénients
- Le clonage vocal n'est pas parfait en raison des données et des ressources de formation limitées.
Questions fréquemment posées
vui est open source et gratuit à utiliser.
Selon nos dernières informations, cet outil ne semble pas avoir d'offre à vie pour le moment, malheureusement.
{toolName} propose trois modèles principaux : Vui.BASE, qui est le point de contrôle de base entraîné sur 40 000 heures de conversations audio ; Vui.ABRAHAM, conçu comme un modèle à locuteur unique capable de réponses contextuellement conscientes, et Vui.COHOST qui permet la communication entre deux locuteurs. Ces modèles répondent à divers cas d'utilisation, allant des interactions conversationnelles fondamentales aux dialogues complexes entre plusieurs parties.
Oui, vous pouvez exécuter {toolName} localement. Pour l'installer, utilisez la commande pip avec la syntaxe suivante : 'pip install -e .'. Cela installera l'outil en mode éditable. Assurez-vous d'avoir Python installé sur votre appareil pour la configuration. Suivez la documentation README dans le dépôt pour des étapes et des exigences détaillées.
Bien que {toolName} offre des capacités de clonage vocal, il est important de noter que le modèle de base peut ne pas produire des résultats parfaits en raison d'un ensemble de données d'entraînement limité. Le modèle n'a pas reçu d'entrées audio étendues, ce qui entraîne des incohérences lors du clonage de voix spécifiques. Les utilisateurs doivent gérer leurs attentes et prendre en compte cet aspect lors de l'utilisation de la fonctionnalité de clonage vocal.
{toolName} utilise une technique de tokenisation audio robuste, développée en collaboration avec Fluac, basée sur le Descript-Audio-Codec. Cela réduit considérablement le nombre de codes audio traités, passant de 83,1 Hz à 21,53 Hz, permettant une gestion des données plus efficace lors du traitement audio. Cette amélioration permet des prédictions vocales plus rapides et plus précises.
Pour des performances optimales, {toolName} fonctionne mieux sur du matériel haute performance, notamment des configurations équipées de GPU NVIDIA 4090, comme l'indique son développeur. L'utilisation d'un tel matériel puissant réduit le temps de traitement et améliore la capacité du modèle à gérer des opérations audio intensives.
Oui, {toolName} connaît des hallucinations, où les résultats peuvent ne pas correspondre à la réalité. C'est un défi courant dans la performance des modèles d'IA, en particulier lorsqu'ils sont entraînés avec des ressources limitées. Les utilisateurs doivent en être conscients et vérifier l'exactitude des résultats critiques.
Intégrer {toolName} avec d'autres outils, tels que Whisper et Audiocraft, peut élargir ses capacités. Whisper aide à une reconnaissance vocale robuste, tandis qu'Audiocraft peut améliorer les fonctionnalités de traitement audio. Explorer ces partenariats peut significativement enrichir l'expérience utilisateur et la fonctionnalité de {toolName}.
{toolName} est hébergé sur GitHub, où les utilisateurs peuvent trouver un support communautaire à travers les problèmes et les discussions. Pour des conseils d'utilisation détaillés, les utilisateurs doivent se référer à la documentation README fournie dans le dépôt. Participer à la communauté peut également donner des conseils précieux pour le dépannage et des informations utiles d'autres utilisateurs.