LibreCrawl
लाइसेंस शुल्क के बिना अनलिमिटेड यूआरएल ऑडिट और जावास्क्रिप्ट रेंडरिंग प्रदान करने वाला ओपन-सोर्स एसईओ क्रॉलर।
Librecrawl.com
क्या यह आपका उपकरण है?
अपडेट और डील्स के लिए अनुसरण करें
LibreCrawl छूट, फीचर रिलीज़ और मूल्य परिवर्तन के लिए अलर्ट प्राप्त करें
समान उपकरण
AlsoAsked
कीवर्ड अनुसंधान उपकरण जो Google के 'लोगों ने भी पूछा' अनुभाग से उपयोगकर्ता प्रश्नों का पता लगाता है
SE Ranking
कीवर्ड ट्रैकिंग, बैकलिंक विश्लेषण और रिपोर्टिंग के लिए ऑल-इन-वन SEO सॉफ़्टवेयर।
Screaming Frog SEO Spider
वेबसाइटों को क्रॉल करता है ताकि तकनीकी SEO समस्याओं की पहचान की जा सके और पृष्ठ प्रदर्शन का विश्लेषण किया जा सके।
Yext
कई स्थानों वाले ब्रांडों के लिए डिजिटल चैनलों में व्यवसाय जानकारी प्रबंधित करें।
Adapty
मोबाइल ऐप डेवलपर्स के लिए लचीले पेवॉल प्रबंधन के साथ इन-ऐप खरीदारी राजस्व का अनुकूलन करें।

LibreCrawl मीडिया गैलरी
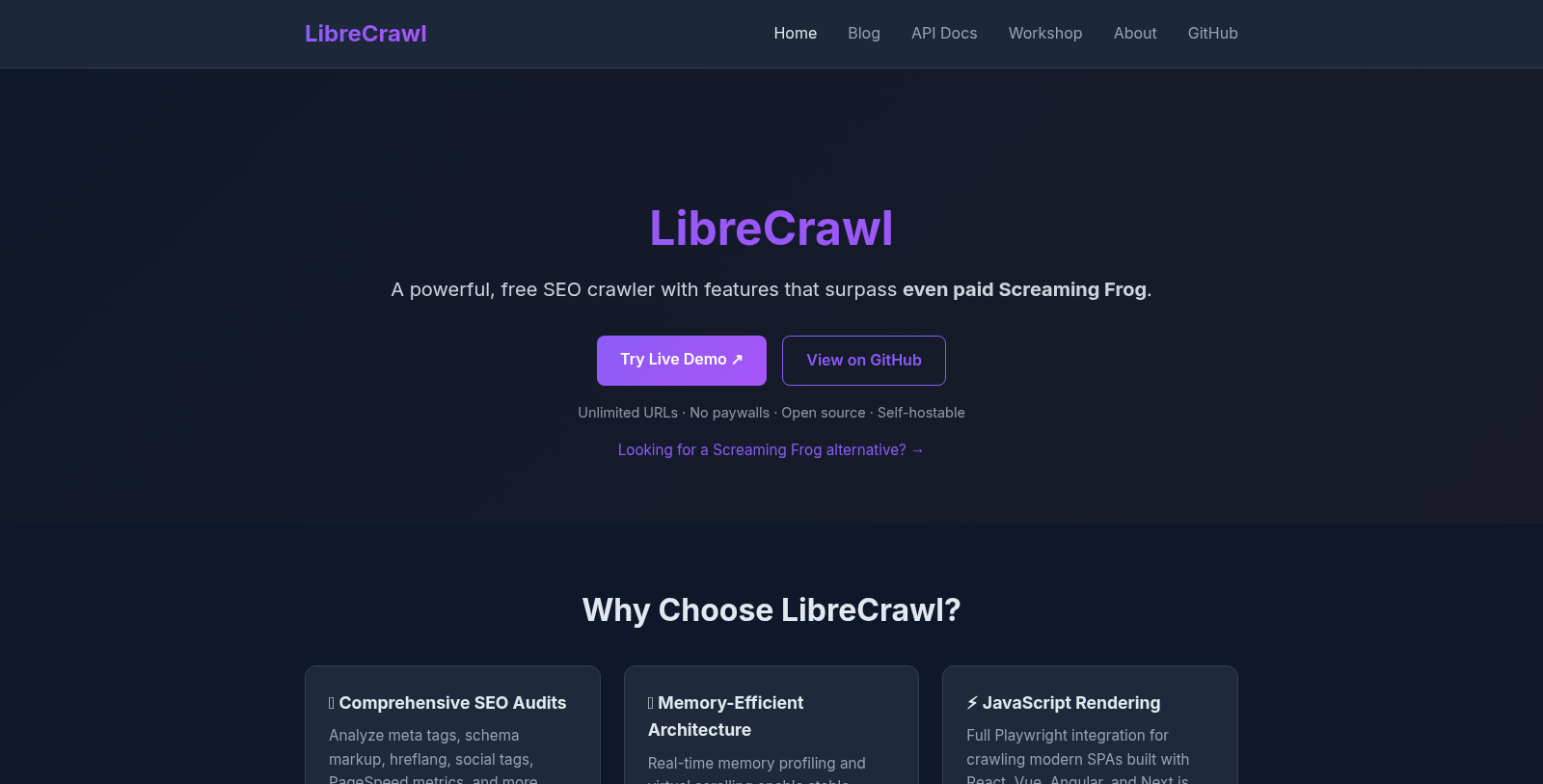
क्या है LibreCrawl?
LibreCrawl एक शक्तिशाली, मुफ्त SEO क्रॉलर है जिसमें ऐसे फीचर्स हैं जो भुगतान किए गए उपकरणों जैसे Screaming Frog को भी पार कर जाते हैं। तकनीकी SEO को लोकतांत्रिक बनाने के मिशन के साथ डिजाइन किया गया, LibreCrawl कृत्रिम सीमाओं जैसे 500 URL कैप और भारी लाइसेंस शुल्क को हटाता है। यह असीमित URL क्रॉलिंग, JavaScript रेंडरिंग, और व्यापक तकनीकी ऑडिट की अनुमति देता है, बिना वित्तीय दबाव के अद्वितीय क्षमताएँ प्रदान करता है।
LibreCrawl को क्यों चुनें?
सुलभता और प्रदर्शन पर ध्यान केंद्रित करते हुए, LibreCrawl विभिन्न मेटा टैग, स्कीमा मार्कअप, hreflang विशेषताएँ, सामाजिक टैग, PageSpeed मेट्रिक्स, और इसके आगे का विश्लेषण करने वाले व्यापक SEO ऑडिट प्रदान करता है। इसकी मेमोरी-प्रभावशाली आर्किटेक्चर सुनिश्चित करता है कि 1 मिलियन URLs को पार करने वाली साइटों के लिए भी क्रॉल को सुचारू रूप से संभाला जा सके, वास्तविक समय की मेमोरी प्रोफाइलिंग और वर्चुअल स्क्रॉलिंग तकनीक के लिए धन्यवाद।
मुख्य सुविधाओं की विशेषताएँ:
- असीमित क्रॉलिंग: बिना सीमा के किसी भी संख्या के URLs का विश्लेषण करें।
- JavaScript रेंडरिंग: आधुनिक SPAs की सटीक क्रॉलिंग की सुविधा देने के लिए पूरी Playwright एकीकरण, जो React, Vue, Angular, और next.js जैसे फ्रेमवर्क द्वारा निर्मित है।
- असीमित निर्यात: अपने डेटा को CSV, JSON, या XML प्रारूपों में निर्यात करें। आवश्यकतानुसार व्यक्तिगत क्षेत्र चुनते हुए बिना किसी सीमा के कई निर्यात करें।
- ओपन सोर्स और स्वयं-होस्ट करने योग्य: GitHub पर MIT लाइसेंस के तहत उपलब्ध पूरी पारदर्शी कोड, उपयोगकर्ताओं को उनके डेटा पर पूरी तरह से नियंत्रण प्रदान करते हुए गोपनीयता सुनिश्चित करता है।
- उन्नत सुविधाएँ: समस्या फ़िल्टरिंग, कस्टम CSS इंजेक्शन, मल्टी-सेशन समर्थन, और विस्तृत लिंक ट्रैकिंग जैसी कई आधुनिक सुविधाएँ उपयोगकर्ताओं को उनके क्रॉलिंग अनुभव को अनुकूलित करने में मदद करती हैं।
विभिन्न उपयोगकर्ता प्रकारों के लिए लाभ:
SEO एजेंसियों के लिए, LibreCrawl टीमों को लाइसेंसिंग लागतों की चिंता से मुक्त करता है, असीमित ग्राहक ऑडिट को कुशलता से निष्पादित करने में सक्षम बनाता है। एजेंसियाँ बिना अपने सॉफ्टवेयर बजट को बढ़ाए दो से बीस टीम सदस्यों तक का विस्तार कर सकती हैं।
Enterprise टीमें बड़े, जटिल वेबसाइटों को संभालने में मूल्य पाती हैं बिना महत्वपूर्ण लागत या सीमाओं का सामना किए। उपकरण की स्वयं-होस्टिंग क्षमताएँ कड़े सुरक्षा और डेटा गोपनीयता मानकों के साथ अनुपालन सुनिश्चित करती हैं, जो एंटरप्राइज की जरूरतों को पूरा करती हैं।
फ्रीलांसरों को शून्य वार्षिक लागत का लाभ मिलता है, उन्हें पेशेवर-स्तरीय विश्लेषण उपकरणों तक पहुंच मिलती है जो उन्हें अपने क्षेत्र में प्रभावी रूप से प्रतिस्पर्धा करने में सक्षम बनाती है। ई-कॉमर्स व्यवसायों को बड़े उत्पाद कैटलॉग का कुशलता से ऑडिट करने में मदद मिलती है, यह सुनिश्चित करते हुए कि हजारों पृष्ठों में SEO अखंडता बनी रहे।
सामग्री प्रकाशक और मीडिया साइटें आंतरिक लिंकिंग रणनीतियों का ऑडिट करके, स्कीमा मार्कअप को मान्य करके, और सामग्री खोजने की क्षमता में सुधार करके अपने उत्पादन को बढ़ाती हैं। इसके अलावा, SaaS और टेक कंपनियाँ सुनिश्चित कर सकती हैं कि उनके मार्केटिंग साइटें और दस्तावेज़ सही आकलनों के माध्यम से खोज इंजन के लिए अनुकूलित हैं जो LibreCrawl द्वारा प्रदान किए गए हैं।
तकनीकी विशेषताएँ: एक गहन नज़र
LibreCrawl तकनीकी SEO विश्लेषण में उत्कृष्ट है। यह टूटे हुए लिंक, डुप्लिकेट कंटेंट, रीडायरेक्ट, और कहीं खोई हुई मेटाडेटा जैसी समस्याओं को पहचानता है जबकि संरचित डेटा कार्यान्वयन को मान्य करता है। उपकरण की उन्नत सुविधाएँ आंतरिक लिंकिंग संरचनाओं और पृष्ठ गति मेट्रिक्स के गहन विश्लेषण की अनुमति देती हैं, हमेशा विकसित होते वेबसाइटों के मजबूत अनुकूलन को सुनिश्चित करती हैं।
समुदाय जुड़ाव:
LibreCrawl समुदाय की भागीदारी पर निर्भर करता है। इसका सफल विकास उपयोगकर्ता फीडबैक और योगदान से उत्पन्न होता है, जो एक सहयोगात्मक पारिस्थितिकी तंत्र का निर्माण करता है। समुदाय के साथ जुड़कर, उपयोगकर्ता भविष्य की सुविधाओं और सुधारों को प्रभावित कर सकते हैं, इसके ओपन-सोर्स सिद्धांत को मज़बूत करते हैं।
शुरुआत करना:
LibreCrawl की स्थापना सीधी है, इसमें बुनियादी कमांड-लाइन ज्ञान की आवश्यकता होती है। उपयोगकर्ता डेमो द्वारा स्थापना के बिना सुविधाओं का परीक्षण करने का विकल्प चुन सकते हैं। जो लोग अनुकूलन में रुचि रखते हैं, LibreCrawl का MIT लाइसेंस विभिन्न आवश्यकताओं के अनुसार व्यापक रूप से संशोधन की अनुमति देता है।
अंत में, LibreCrawl पारंपरिक क्रॉलिंग उपकरणों के लिए एक शक्तिशाली विकल्प के रूप में खड़ा है, जो उन्नत SEO क्षमताओं तक पहुँच को बढ़ावा देता है। इसकी मजबूत सुविधाओं की श्रृंखला और शून्य लागत की प्रतिबद्धता के साथ, यह बिना समझौता किए आधुनिक उद्योग की मांगों को प्रभावी ढंग से पूरा करता है।
फायदे और नुकसान
फायदे
- किसी भी कृत्रिम सीमा या भुगतान दीवार के बिना असीमित URL क्रॉलिंग क्षमताएँ।
- जावा स्क्रिप्ट रेंडरिंग और वास्तविक समय मेमोरी प्रोफाइलिंग जैसी उन्नत सुविधाएँ प्रदान करता है।
- पूरी तरह से ओपन-सोर्स है जिसमें तैनाती और डेटा गोपनीयता पर पूरी नियंत्रण है।
नुकसान
- व्यावसायिक समर्थन और लॉग फ़ाइल विश्लेषण जैसी विशेषताओं की कमी है।
अक्सर पूछे जाने वाले प्रश्न
LibreCrawl बिना किसी लागत के उपलब्ध है।
हमारी नवीनतम जानकारी के अनुसार, इस उपकरण में वर्तमान में जीवनकाल सौदा उपलब्ध नहीं है, दुर्भाग्यवश।
LibreCrawl कई उन्नत विशेषताएँ प्रदान करता है, जिसमें वास्तविक समय की मेमोरी प्रोफाइलिंग, 1 मिलियन से अधिक URLs के स्थिर क्रॉल के लिए वर्चुअल स्क्रॉलिंग, और Playwright का उपयोग करके निर्मित JavaScript रेंडरिंग शामिल है। इसमें समस्या फ़िल्टरिंग, समानांतर परियोजनाओं के लिए मल्टी-सेशन समर्थन, कस्टम CSS इंजेक्शन, और CSV, JSON, या XML प्रारूपों में असीमित निर्यात भी शामिल हैं। ये विशेषताएँ अन्य उपकरणों में अक्सर पाई जाने वाली सीमाओं के बिना एक समग्र तकनीकी SEO ऑडिट अनुभव प्रदान करने के लिए डिज़ाइन की गई हैं।
LibreCrawl को गोपनीयता पर एक मजबूत ध्यान केंद्रित करते हुए डिज़ाइन किया गया है। यह उपयोगकर्ताओं का ट्रैक नहीं करता है और न ही क्रॉलिंग व्यवहार पर एनालिटिक्स جمع करता है। इसके अलावा, एक ओपन-सोर्स टूल के रूप में, उपयोगकर्ताओं को कोडबेस तक पूरी पहुंच है, जिससे वे यह पुष्टि कर सकते हैं कि कोई डेटा तीसरे पक्ष के सर्वरों पर नहीं भेजा जा रहा है। अधिकतम नियंत्रण के लिए, उपयोगकर्ताओं को अपने स्वयं के बुनियादी ढांचे पर LibreCrawl को स्वयं-होस्ट करने के लिए प्रोत्साहित किया जाता है, यह सुनिश्चित करते हुए कि सभी क्रॉल डेटा निजी और उनके नियंत्रण में बने रहें।
जी हां, LibreCrawl को स्वयं-होस्ट किया जा सकता है, जिससे उपयोगकर्ता इसे अपने खुद के सर्वरों पर चला सकते हैं। स्थापना प्रक्रिया उनके लिए आसान है जिनके पास बुनियादी सर्वर प्रशासन कौशल हैं। उपयोगकर्ताओं के पास Python 3.8 या उसके बाद का संस्करण instalado होना चाहिए, और सेटअप में रिपोजिटरी को क्लोन करना, आवश्यक निर्भरताएं स्थापित करना और ब्राउज़र बाइनरी प्राप्त करने के लिए Playwright इंस्टॉलेर को चलाना शामिल है। विस्तृत सेटअप निर्देश GitHub रिपोजिटरी में उपलब्ध हैं।
LibreCrawl उपयोगकर्ताओं को किसी भी प्रतिबंध या पेवॉल के बिना अनगिनत URLs को क्रॉल करने की अनुमति देता है। अन्य उपकरणों की तरह नहीं जो सब्सक्रिप्शन स्तर द्वारा क्रॉल लिमिट को सीमित करते हैं, LibreCrawl की एकमात्र सीमा उपयोगकर्ता के हार्डवेयर क्षमता है। यह उपकरण उन्नत मेमोरी प्रबंधन तकनीकों के साथ बनाया गया है, जिससे यह बड़े साइटों को प्रभावी ढंग से संभालने में सक्षम है, यहां तक कि उन साइटों को जिनमें लाखों पृष्ठ हैं।
LibreCrawl कई एक्सपोर्ट फॉर्मेट्स का समर्थन करता है, जिनमें CSV, JSON, और XML शामिल हैं, रिपोर्टिंग या अन्य उपकरणों के साथ इंटीग्रेशन के लिए। इसके अलावा, यह एक कस्टमाइज़ेबल एक्सपोर्ट विकल्प प्रदान करता है जो उपयोगकर्ताओं को अपने रिपोर्ट में शामिल करने के लिए विशिष्ट क्षेत्रों का चयन करने की अनुमति देता है। बिना किसी आकार या आवृत्ति की प्रतिबंध के अनलिमिटेड एक्सपोर्ट विकल्प उपयोगकर्ताओं को ज़रूरत के अनुसार जितनी भी रिपोर्ट बनानी हो, बनाने की सुविधा देता है।
हाँ, LibreCrawl का एक सक्रिय समुदाय है जो GitHub के माध्यम से सहायता प्रदान करता है। उपयोगकर्ता बग की रिपोर्ट कर सकते हैं, नए फीचर्स का अनुरोध कर सकते हैं, और GitHub Issues और Discussions सेक्शन में समस्याओं पर चर्चा कर सकते हैं। कई सामान्य सवालों के जवाब डॉक्यूमेंटेशन में भी दिए गए हैं। समुदाय के लिए तेजी से प्रतिक्रिया देना जाना जाता है, अक्सर 24-48 घंटे के भीतर, जिससे उपयोगकर्ताओं को समस्याओं को प्रभावी तरीके से हल करने में मदद मिलती है।
छोटे से लेकर मध्यम आकार के साइट्स (100,000 URLs से कम) के लिए, 8GB RAM और एक आधुनिक प्रोसेसर वाला मशीन पर्याप्त है। हालांकि, बड़े क्रॉल के लिए, विशेष रूप से उन क्रॉल के लिए जिनमें लाखों URLs शामिल हैं, 16-32GB RAM होना बेहतर है। LibreCrawl में एक मेमोरी प्रोफाइलिंग फीचर शामिल है जो उपयोगकर्ताओं को संसाधन उपयोग की निगरानी करने और उनकी विशेष हार्डवेयर क्षमताओं के आधार पर सेटिंग्स को ऑप्टिमाइज़ करने में मदद करता है।
बिल्कुल! LibreCrawl ओपन सोर्स है और इसे MIT लाइसेंस के तहत लाइसेंसित किया गया है, जिससे उपयोगकर्ता रेपो को फोर्क कर सकते हैं, सोर्स कोड को संशोधित कर सकते हैं, और आवश्यकतानुसार विशेष सुविधाएँ या कस्टमाइज़ेशन जोड़ सकते हैं। उपयोगकर्ता समस्या पहचान नियमों को बदल सकते हैं, नए निर्यात प्रारूप लागू कर सकते हैं, या यहां तक कि एक कस्टम उपयोगकर्ता इंटरफ़ेस भी बना सकते हैं। जबकि संशोधनों को निजी रखा जा सकता है, समुदाय के लाभ के लिए मुख्य प्रोजेक्ट में योगदान देने की सिफारिश की जाती है।