अपडेट और डील्स के लिए अनुसरण करें
vui छूट, फीचर रिलीज़ और मूल्य परिवर्तन के लिए अलर्ट प्राप्त करें
समान उपकरण
David AI
बोलने और संवाद AI मॉडलों के प्रशिक्षण के लिए चयनित ऑडियो डेटा सेट प्रदान करता है।
MetaVoice
AI-शक्ति वाली आवाज़ प्रणाली जो पारंपरिक बारी-बारी बातचीत के बिना स्वाभाविक और भावनात्मक रूप से जागरूक संवादों को सक्षम बनाती है।
Synthesia
140 से अधिक भाषाओं में विस्तृत उत्पादन के बिना आकर्षक AI-निर्मित वीडियो में टेक्स्ट को बदलें।
Coval
कृत्रिम बुद्धिमत्ता वॉयस और चैट एजेंटों का अनुकरण और मूल्यांकन करें ताकि परीक्षण और प्रदर्शन अनुकूलन प्रभावी हो सके।
Voicemod
गिमिंग और लाइव स्ट्रीमिंग के लिए विभिन्न प्रभावों के साथ अपने स्वर को वास्तविक समय में बदलें।

vui मीडिया गैलरी
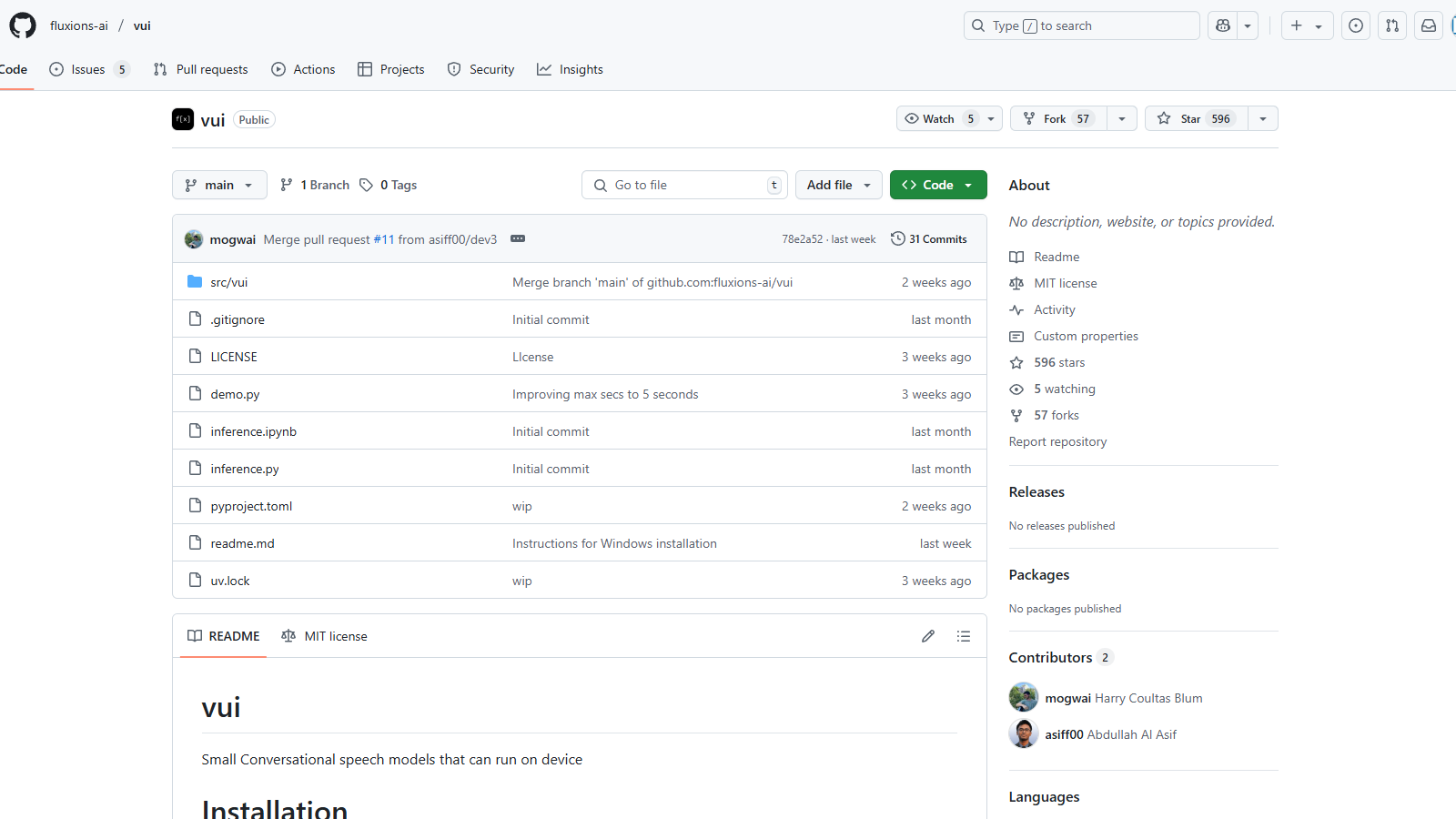
क्या है vui?
VUI एक अभिनव उपकरण है जो संवादात्मक भाषण मॉडलों पर केंद्रित है जिसे सीधे उपकरणों पर काम करने के लिए डिज़ाइन किया गया है,Speech संबंधित कार्यों के लिए एक कुशल और उपयोगकर्ता-अनुकूल समाधान प्रदान करता है। VUI टूलकिट में उपलब्ध प्राथमिक मॉडल व्यापक डेटा सेट पर प्रशिक्षित हैं, जिससे वे ऑडियो को प्रभावी ढंग से संसाधित कर सकते हैं और संदर्भात्मक रूप से प्रासंगिक प्रतिक्रियाएँ उत्पन्न कर सकते हैं।
अपडेटेड प्रमुख विशेषताएँ:
- कई मॉडल: Vui विभिन्न प्रकार के संवादात्मक इंटरैक्शन के लिए अनुकूलित Vui.BASE, Vui.ABRAHAM और Vui.COHOST सहित कई प्रकार के मॉडल पेश करता है। Vui.BASE को 40k घंटे के ऑडियो वार्तालाप पर विशेष रूप से प्रशिक्षित किया गया है, जिससे विभिन्न अनुप्रयोगों के लिए एक मजबूत आधार प्रदान किया गया है।
- वॉयस क्लोनिंग: उपयोगकर्ता अग्रिम डेटा सेट के आधार पर उचित सटीकता के साथ आवाजों को पुन: उत्पन्न करने की क्षमताओं के लिए मॉडलों का लाभ उठा सकते हैं। आवाजों को क्लोन करने की क्षमता बढ़ाई गई है, लेकिन यह नोट किया गया है कि प्रशिक्षण डेटा में सीमाओं के कारण परिणाम सही नहीं हो सकते हैं।
- प्रभावशीलता: मॉडल को उपकरणों पर प्रभावी ढंग से कार्य करने के लिए डिज़ाइन किया गया है बिना व्यापक क्लाउड संसाधनों की आवश्यकता के, जिससे यह उच्च प्रतिक्रियाशीलता और कम विलंबता की आवश्यकता वाले अनुप्रयोगों के लिए आदर्श बनाता है। VUI मॉडल एक लामा-आधारित ट्रांसफार्मर का उपयोग करते हैं जो ऑडियो टोकन की भविष्यवाणी करता है, जो उनके परिचालन दक्षता में सुधार के लिए मॉडल आर्किटेक्चर में प्रगति को दिखाता है।
- ऑडियो टोकनाइजेशन: एक महत्वपूर्ण विशेषता फ्लोअक ऑडियो टोकनाइज़र है, जो प्रति सेकंड कोड की संख्या को प्रभावी ढंग से कम करता है, जिससे समग्र प्रसंस्करण गति 83.1Hz से 21.53Hz तक बढ़ जाती है।
स्थापना और उपयोग:
VUI का उपयोग शुरू करने के लिए, उपयोगकर्ता आसानी से कमांड pip install -e . का उपयोग करते हुए पैकेज प्रबंधक के माध्यम से इसे स्थापित कर सकते हैं। स्थापना प्रक्रिया सीधी है, और python demo.py चलाकर एक डेमो चलाया जा सकता है। यह लचीलापन विकासकर्ताओं को विभिन्न अनुप्रयोगों में मॉडलों को लागू करने की अनुमति देता है, जिससे निर्बाध भाषण मान्यता और उत्पादन कार्यात्मकताओं के साथ उपयोगकर्ता अनुभव को बढ़ाया जाता है।
चुनौतियाँ और विचार:
हालांकि मॉडल प्रभावशाली क्षमताएँ दिखाते हैं, वे सीमाओं के बिना नहीं हैं। उपयोगकर्ता कुछ अनियमितताएँ अनुभव कर सकते हैं, जैसे कि कभी-कभी幻觉, जो तब होती हैं जब AI ऐसी प्रतिक्रियाएँ उत्पन्न करता है जो इसके प्रशिक्षण डेटा पर आधारित नहीं होती हैं। इसे विकास टीम द्वारा स्वीकार किया जाता है क्योंकि वे निरंतर सुधार और समुदाय सहभागिता की कोशिश कर रहे हैं।
इन चुनौतियों के बावजूद, VUI मॉडल संवादात्मक AI में एक महत्वपूर्ण उन्नति का प्रतिनिधित्व करते हैं, विशेष रूप से उन परियोजनाओं के लिए जो आवाज के माध्यम से इंटरैक्टिविटी को बढ़ाने का लक्ष्य रखते हैं। विकास टीम निरंतर सुधार, अंतर्दृष्टि साझा करने और सामुदायिक फीडबैक के आधार पर मुद्दों को संबोधित करने पर जोर देती है। विकास के प्रति इस प्रतिबद्धता को अत्याधुनिक तकनीकों और अन्य ओपन-सोर्स परियोजनाओं के साथ सहयोगात्मक प्रयासों के उपयोग के द्वारा समर्थित किया जाता है।
श्रेष्ठता:
VUI का विकास कई ओपन-सोर्स परियोजनाओं से योगदान स्वीकार करता है, जिसमें OpenAI द्वारा Whisper और Facebook Research द्वारा Audiocraft शामिल हैं, जो भाषण प्रसंस्करण के लिए मजबूत उपकरण बनाने की ओर सामुदायिक प्रयास को दर्शाता है। इन सहयोगों के माध्यम से, VUI अपने प्रस्तावों को बढ़ाता है और ऑडियो प्रसंस्करण प्रौद्योगिकी के तेज़ी से विकसित क्षेत्र में प्रासंगिकता बनाए रखता है।
फायदे और नुकसान
फायदे
- डिवाइस पर बिना क्लाउड समर्थन की आवश्यकता के चलने वाले छोटे बातचीत भाषण मॉडल प्रदान करता है।
- एकल स्पीकर और डुअल स्पीकर मॉडलों के लिए संदर्भ-ज्ञानयुक्त मॉडल विभिन्न अनुप्रयोगों के लिए उपलब्ध हैं।
- ऑडियो टोकन की भविष्यवाणी के लिए लामा-आधारित ट्रांसफार्मर का उपयोग करता है, जिससे प्रदर्शन में सुधार होता है।
नुकसान
- आवाज़ क्लोनिंग सीमित प्रशिक्षण डेटा और संसाधनों के कारण परिपूर्ण नहीं है।
अक्सर पूछे जाने वाले प्रश्न
vui ओपन सोर्स है और उपयोग के लिए मुफ्त है।
हमारी नवीनतम जानकारी के अनुसार, इस उपकरण में वर्तमान में जीवनकाल सौदा उपलब्ध नहीं है, दुर्भाग्यवश।
{toolName} तीन प्रमुख मॉडल प्रदान करता है: Vui.BASE, जो 40,000 घंटे की ऑडियो वार्तालाप पर प्रशिक्षित मूल चेकपॉइंट है; Vui.ABRAHAM, जिसे एकल-वार्ताकार मॉडल के रूप में डिज़ाइन किया गया है जो संदर्भ-जागरूक उत्तर देने में सक्षम है; और Vui.COHOST, जो दो वार्ताकारों के बीच संचार की सुविधा प्रदान करता है। ये मॉडल विभिन्न उपयोग के मामलों के लिए काम करते हैं, जो बुनियादी संवादात्मक इंटरैक्शन से लेकर कई पक्षों के बीच जटिल वार्तालाप तक फैले हुए हैं।
हाँ, आप {toolName} को स्थानीय रूप से चला सकते हैं। इसे स्थापित करने के लिए, निम्नलिखित सिंटैक्स के साथ pip कमांड का उपयोग करें: 'pip install -e .' यह टूल को संपादनीय मोड में स्थापित करेगा। सुनिश्चित करें कि आपके डिवाइस पर सेटअप के लिए Python स्थापित है। विस्तृत चरणों और आवश्यकताओं के लिए रिपॉजिटरी में README दस्तावेज़ का पालन करें।
हालाँकि {toolName} वॉयस क्लोनिंग की क्षमताएँ प्रदान करता है, यह महत्वपूर्ण है कि यह ध्यान में रखा जाए कि आधार मॉडल सीमित प्रशिक्षण डेटासेट के कारण परिपूर्ण परिणाम नहीं दे सकता। मॉडल को व्यापक ऑडियो इनपुट नहीं मिले हैं, जिसके कारण विशेष आवाज़ों को क्लोन करते समय असंगतताएँ उत्पन्न होती हैं। उपयोगकर्ताओं को अपनी अपेक्षाओं का प्रबंधन करना चाहिए और वॉयस क्लोनिंग फीचर का उपयोग करते समय इस पहलू पर विचार करना चाहिए।
{toolName} एक मजबूत ऑडियो टोकनाइजेशन तकनीक का उपयोग करता है, जिसे फ्लुआक (Fluac) के साथ मिलकर विकसित किया गया है, जो Descript-Audio-Codec पर आधारित है। यह ऑडियो कोड्स की संख्या को काफी कम करता है, 83.1 Hz से 21.53 Hz तक, जिससे ऑडियो प्रोसेसिंग के दौरान डेटा को अधिक कुशलता से संभालना संभव होता है। इस सुधार से आवाज की भविष्यवाणियों में तेजी और सटीकता बढ़ती है।
सर्वोत्तम प्रदर्शन के लिए, {toolName} को उच्च-प्रदर्शन वाले हार्डवेयर पर चलाना सबसे अच्छा है, विशेष रूप से ऐसे सेटअप पर जो NVIDIA 4090 GPUs से लैस हैं, जैसा कि इसके डेवलपर द्वारा बताया गया है। इस प्रकार के शक्तिशाली हार्डवेयर का उपयोग प्रसंस्करण समय को कम करता है और मॉडल की गहन ऑडियो संचालन को संभालने की क्षमता को बढ़ाता है।
हाँ, {toolName} हालुसीनेशन का अनुभव करता है, जहाँ आउटपुट वास्तविकता से मेल नहीं खा सकता। यह AI मॉडल के प्रदर्शन में एक सामान्य चुनौती है, विशेष रूप से सीमित संसाधनों के साथ प्रशिक्षण के समय। उपयोगकर्ताओं को इस पर ध्यान देना चाहिए और महत्वपूर्ण आउटपुट की सटीकता की पुष्टि करनी चाहिए।
{toolName} को अन्य उपकरणों जैसे कि Whisper और Audiocraft के साथ इंटीग्रेट करने से इसकी क्षमताओं में वृद्धि हो सकती है। Whisper मजबूत स्पीच पहचान में मदद करता है, जबकि Audiocraft ऑडियो प्रोसेसिंग सुविधाओं को बेहतर बना सकता है। इन साझेदारियों की खोज से {toolName} के उपयोगकर्ता अनुभव और कार्यक्षमता को काफी हद तक बढ़ाया जा सकता है।
{toolName} GitHub पर होस्ट किया गया है, जहाँ उपयोगकर्ता समस्याओं और चर्चाओं के माध्यम से सामुदायिक सहायता प्राप्त कर सकते हैं। विस्तृत उपयोग मार्गदर्शन के लिए, उपयोगकर्ताओं को रिपॉजिटरी में उपलब्ध README दस्तावेज़ का संदर्भ लेना चाहिए। सामुदायिक सहभागिता भी अन्य उपयोगकर्ताओं से मूल्यवान समस्या निवारण टिप्स और अंतर्दृष्टि प्रदान कर सकती है।