Firecrawl
Un'API per il scraping e la strutturazione efficiente dei dati web, progettata per applicazioni AI.
Firecrawl.dev
Categoria
Tipo
Tag
Modello di Prezzo
È questo il tuo strumento?
Segui per aggiornamenti e offerte
Ricevi avvisi su sconti, nuove funzionalità e cambiamenti di prezzo per Firecrawl
Strumenti Simili
Moonshot
Un assistente AI che migliora il processo decisionale attraverso risposte interattive e intelligenti.
01.AI
Piattaforma AI che consente alle imprese di implementare soluzioni personalizzate e integrare il deep learning nei flussi di lavoro esistenti.
Google DeepMind
Sviluppare sistemi di intelligenza artificiale per la scoperta scientifica, la sanità e affrontare le sfide sociali.
Amazon Bedrock AgentCore
Distribuisci e gestisci agenti AI in modo sicuro su larga scala.
DeepSeek
Accedi a intuizioni guidate dall'IA e capacità di ragionamento avanzate tramite chat e integrazione API.

Galleria multimediale di Firecrawl

Firecrawl (recensione) video
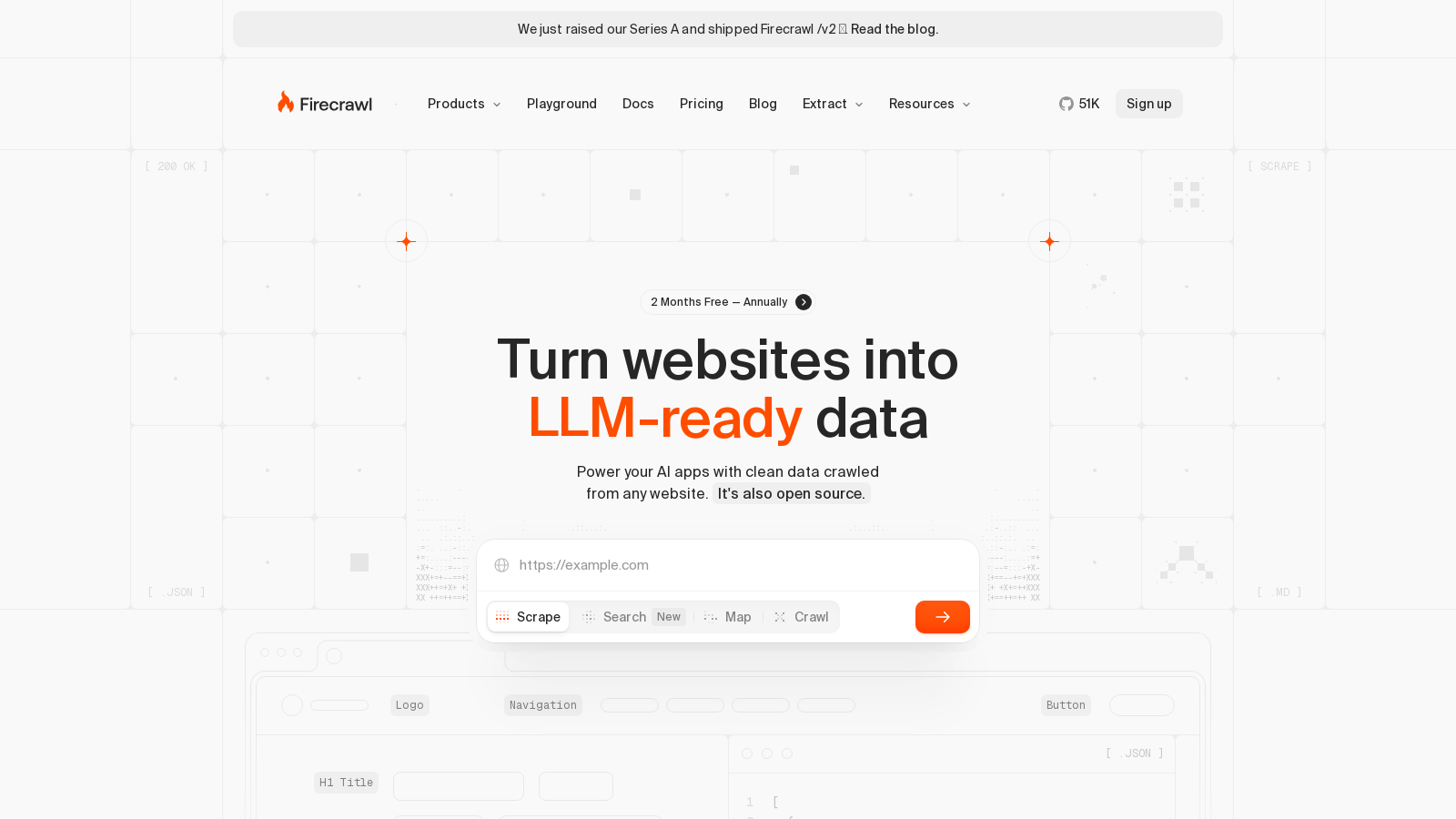
Screenshot di Firecrawl
Cos'è Firecrawl?
Firecrawl è un avanzato API per il crawling, scraping e ricerca web progettato specificamente per applicazioni di intelligenza artificiale. Permette agli sviluppatori di estrarre rapidamente ed efficientemente dati strutturati dal web, una necessità per alimentare agenti AI e creare applicazioni robuste che utilizzano dati web in tempo reale. Con Firecrawl, gli utenti possono accedere e sfruttare i dati provenienti da tutto internet in un formato pulito e organizzato.
Una delle caratteristiche distintive di Firecrawl è la sua capacità di trasformare qualsiasi sito web in dati pronti per LLM. Questo consente agli sviluppatori di raccogliere informazioni senza sforzo e presentarle in vari formati adatti per applicazioni AI, inclusi Markdown, JSON e persino screenshot. Firecrawl riduce significativamente le barriere per raccogliere e utilizzare i dati web, rendendo più facile per gli sviluppatori integrare l'intelligenza web nelle loro soluzioni AI.
Caratteristiche Principali
Firecrawl è costruito attorno a principi fondamentali che garantiscono prestazioni e affidabilità. L'API vanta una copertura del 96% del web, inclusi pagine pesanti in JavaScript e protette, che spesso rappresentano una sfida per i scraper tradizionali. Rimuovendo la necessità di proxy e offrendo un'interfaccia API facile da usare, Firecrawl semplifica il flusso di lavoro per la raccolta di dati web. È progettato per la velocità, fornendo risultati in meno di un secondo, cruciale per applicazioni in tempo reale.
Ultimi Miglioramenti nella v2
Con il recente lancio della versione 2, Firecrawl ha introdotto una serie di potenti funzionalità. Queste includono scraping 10 volte più veloce grazie a una cache intelligente, una funzione di crawling semantico che consente agli utenti di descrivere le informazioni desiderate in inglese semplice, e un nuovo formato di riepilogo che estrae rapidamente informazioni. Inoltre, la funzionalità di ricerca ora supporta richieste di immagini e notizie su richiesta, arricchendo i tipi di dati che gli sviluppatori possono recuperare.
Piani Tariffari Flessibili
Firecrawl offre una varietà di livelli tariffari per soddisfare diverse esigenze degli utenti. Gli utenti possono iniziare con un piano gratuito che consente di raccogliere 500 pagine e include un numero limitato di crediti. I piani a pagamento offrono accesso fino a 3.000 crediti mensili per progetti più piccoli e fino a 500.000 crediti mensili per iniziative su larga scala, garantendo che tutti gli utenti possano trovare un livello adatto alle proprie necessità. Inoltre, la struttura dei prezzi è trasparente, rendendo più semplice per gli sviluppatori scegliere le migliori opzioni per i loro progetti.
Casi d'Uso e Applicazioni
La versatilità di Firecrawl si manifesta attraverso la sua moltitudine di applicazioni. Le organizzazioni utilizzano l'API per arricchire i lead, monitorare i prezzi competitivi, strategie di marketing digitale avanzate e persino per ricerche accademiche raccogliendo dati da varie fonti online. Le piattaforme AI migliorano le loro funzionalità con Firecrawl, costruendo chatbot dinamici e basi di conoscenza continuamente aggiornate con le ultime informazioni.
Integrazioni e Supporto Comunitario
Progettato con una mentalità orientata agli sviluppatori, Firecrawl offre una documentazione estesa e supporto comunitario, aiutando gli utenti ad imparare rapidamente come utilizzare efficacemente la tecnologia. Si integra senza problemi con numerose piattaforme e strumenti, semplificando l'impostazione per i team che desiderano incorporare le sue funzionalità nei loro flussi di lavoro. La comunità, supportata dall'impegno open-source di Firecrawl, assicura che gli utenti possano contribuire, adattare e migliorare continuamente il prodotto.
Impegno per l'Open Source
Firecrawl è dedicato a mantenere un framework open-source. Questa trasparenza promuove i contributi della comunità, garantendo miglioramenti continui del prodotto e affidabilità. Gli utenti sono incoraggiati a partecipare al processo di sviluppo di Firecrawl, attenersi alle migliori pratiche nello sviluppo software e beneficiare di una soluzione che si evolve attraverso sforzi guidati dalla comunità.
Unisciti al Futuro dei Dati Web Potenziati dall'AI
In conclusione, Firecrawl getta le basi affinché gli sviluppatori possano creare applicazioni potenti fornendo accesso ai dati web in tempo reale. Che si tratti di migliorare le interazioni con i clienti attraverso intuizioni guidate dall'AI o raccogliere dati critici per la ricerca, Firecrawl si distingue come una risorsa inestimabile. Con la sua API scalabile e un'ampia gamma di funzionalità, è un attore formidabile nel moderno panorama dello scraping web.
Pro e Contro
Pro
- Fornisce dati web su larga scala, gestendo in modo efficiente siti dinamici e ricchi di JavaScript.
- Offre un'API low-code che semplifica l'estrazione dei dati in vari formati come JSON e Markdown.
- Si integra perfettamente con strumenti popolari e supporta lo sviluppo open source.
Contro
- Gli utenti possono affrontare una curva di apprendimento nel passaggio da altri strumenti di scraping.
Domande Frequenti
Firecrawl offre un piano gratuito con crediti limitati, con crediti aggiuntivi disponibili.
Secondo le nostre ultime informazioni, questo strumento non sembra avere un affare a vita al momento, purtroppo.
Firecrawl utilizza tecniche di scraping intelligenti per affrontare i contenuti dinamici generati da JavaScript. La piattaforma simula interazioni degli utenti, come clic e scrolling, per garantire che tutto il contenuto rilevante venga catturato. Inoltre, impiega tempi di attesa intelligenti per consentire il caricamento completo delle pagine prima dello scraping, migliorando l'affidabilità e la completezza dei dati.
Firecrawl può estrarre e fornire dati in diversi formati, tra cui JSON e Markdown. Questa flessibilità consente agli sviluppatori di integrare facilmente i dati estratti nelle loro applicazioni, che si tratti di sistemi AI, applicazioni web o strumenti di analisi dei dati.
Firecrawl è progettato per rispettare le regole stabilite nel file robots.txt di un sito web, che controlla come i motori di ricerca e i crawler possono interagire con il sito. Inoltre, ha funzionalità integrate per affrontare le comuni sfide dello scraping web, comprese le limitazioni di frequenza e la cache, garantendo un'interferenza minima con i siti web target.
Sì, Firecrawl è progettato esplicitamente per la scalabilità e può gestire in modo efficiente progetti di scraping web su larga scala. Supporta richieste ad alto volume e può fare scraping di più pagine simultaneamente. Funzionalità come lo scraping in batch e la memorizzazione intelligente migliorano le sue prestazioni per le esigenze di estrazione di dati estensive.
Firecrawl semplifica l'arricchimento dei lead consentendo ai team di vendita di estrarre efficientemente informazioni dalle directory e raccogliere dati aziendali preziosi, inclusi dettagli di contatto e notizie aziendali. Questi dati in tempo reale aiutano a mantenere aggiornati i profili dei lead e arricchiscono i sistemi CRM, consentendo una migliore comunicazione e decisione.
Sì, Firecrawl è progettato per un'integrazione fluida con una varietà di strumenti e piattaforme, inclusi ambienti di sviluppo AI e flussi di lavoro dei dati. Fornisce SDK per i linguaggi di programmazione più popolari e supporta il Model Context Protocol (MCP) per una maggiore interoperabilità, rendendolo accessibile per vari casi d'uso.
Firecrawl può essere utilizzato per una vasta gamma di applicazioni, tra cui potenziare chatbot AI con contenuti web aggiornati, arricchire i lead per i team di vendita, monitorare le attività dei concorrenti e condurre ricerche approfondite aggregando dati da più fonti. La sua versatilità lo rende adatto sia per sviluppatori che per aziende in vari settori.
Firecrawl utilizza algoritmi sofisticati per pulire e strutturare i dati estratti dai siti web, garantendo che siano utilizzabili e affidabili. La piattaforma incorpora la gestione degli errori per gestire le richieste fallite e offre meccanismi di caching per prevenire la raccolta di dati duplicati. Questo assicura agli utenti di ottenere dati di alta qualità e utilizzabili per le loro applicazioni.