vui
Modelli di linguaggio conversazionale in esecuzione sul dispositivo.
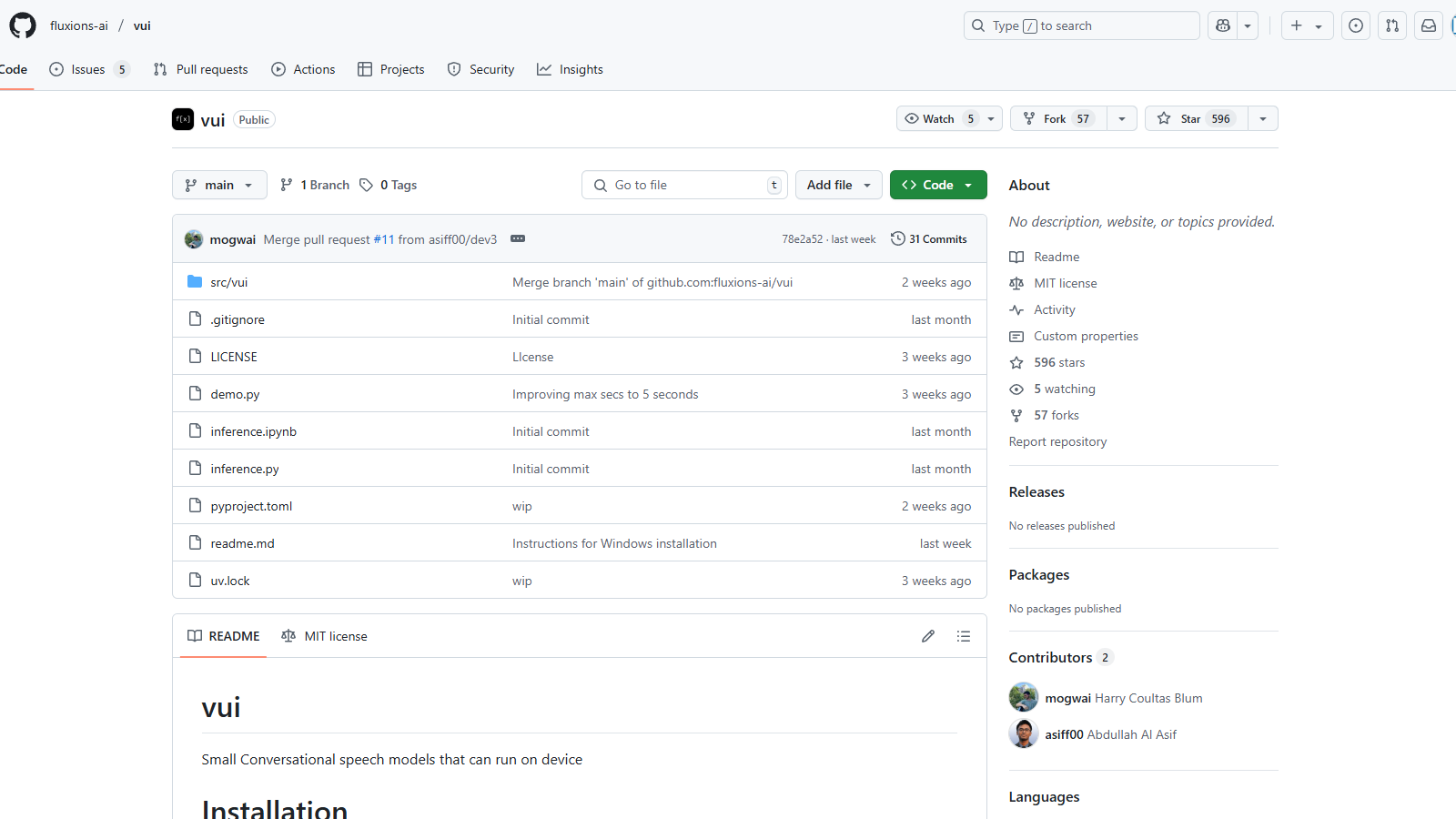
Github.com
È questo il tuo strumento?
Segui per aggiornamenti e offerte
Ricevi avvisi su sconti, nuove funzionalità e cambiamenti di prezzo per vui
Strumenti Simili
David AI
Fornisce set audio curati per addestrare modelli di AI per il parlato e la conversazione.
Voicemod
Cambia la tua voce in tempo reale con vari effetti per i giochi e lo streaming live.
Coval
Simula e valuta agenti vocali e di chat AI per test efficaci e ottimizzazione delle prestazioni.
NoteWave
Trascrive e riassume le riunioni in tempo reale, catturando decisioni chiave e azioni da intraprendere.
Candy AI
Interagisci con compagni AI personalizzabili tramite chat, voce e video per interazioni personali.

Galleria multimediale di vui
Cos'è vui?
VUI è uno strumento innovativo incentrato su modelli di discorso conversazionale progettati per funzionare direttamente sui dispositivi, offrendo una soluzione efficiente e intuitiva per compiti legati al discorso. I modelli principali disponibili nel toolkit VUI sono addestrati su ampi dataset, consentendo loro di elaborare audio in modo efficace e produrre risposte contestualmente rilevanti.
Funzionalità Chiave Aggiornate:
- Modelli Multipli: Vui offre una varietà di modelli tra cui Vui.BASE, Vui.ABRAHAM e Vui.COHOST, ognuno ottimizzato per diversi tipi di interazioni conversazionali. Vui.BASE è stato specificamente addestrato su 40k ore di conversazioni audio, fornendo una base solida per varie applicazioni.
- Clonazione della Voce: Gli utenti possono sfruttare i modelli per capacità di clonazione della voce, consentendo loro di replicare voci con una ragionevole precisione basata sui dataset pre-addestrati. La capacità di clonare voci è migliorata, ma si nota che i risultati potrebbero non essere perfetti a causa delle limitazioni nei dati di addestramento.
- Efficienza: I modelli sono progettati per funzionare in modo efficace sui dispositivi senza bisogno di estese risorse cloud, rendendoli ideali per applicazioni che richiedono una bassa latenza e un'alta reattività. I modelli VUI utilizzano un trasformatore basato su llama che predice token audio, mostrando progressi nell'architettura del modello che migliorano la loro efficienza operativa.
- Tokenizzazione Audio: Una caratteristica significativa è il tokenizzatore audio fluac, che riduce efficacemente il numero di codici al secondo, aumentando la velocità di elaborazione complessiva da 83.1hz a 21.53hz.
Installazione e Utilizzo:
Per iniziare a utilizzare VUI, gli utenti possono facilmente installarlo tramite un gestore di pacchetti utilizzando il comando pip install -e .. Il processo di installazione è semplice e una demo può essere eseguita lanciando python demo.py. Questa flessibilità consente agli sviluppatori di implementare i modelli in varie applicazioni, migliorando le esperienze degli utenti con funzionalità fluide di riconoscimento e generazione del discorso.
Sfide e Considerazioni:
Sebbene i modelli mostrino capacità impressionanti, non sono privi di limitazioni. Gli utenti possono sperimentare alcune stranezze, come occasionali allucinazioni, che si verificano quando l'AI genera risposte non basate sui propri dati di addestramento. Questa realtà è riconosciuta dal team di sviluppo mentre si sforzano per un miglioramento continuo e un coinvolgimento della comunità.
Nonostante queste sfide, i modelli VUI rappresentano un avanzamento significativo nell'IA conversazionale, in particolare per progetti mirati a migliorare l'interattività attraverso la voce. Il team di sviluppo sottolinea il miglioramento continuo, condividendo intuizioni e affrontando problemi basati sul feedback della comunità. Questo impegno per lo sviluppo è sostenuto dall'uso di tecnologie all'avanguardia e sforzi collaborativi con altri progetti open-source.
Attribuzioni:
Lo sviluppo di VUI riconosce i contributi di diversi progetti open-source, tra cui Whisper di OpenAI e Audiocraft di Facebook Research, dimostrando uno sforzo collettivo verso la costruzione di strumenti robusti per l'elaborazione del discorso. Grazie a queste collaborazioni, VUI migliora le proprie offerte e mantiene rilevanza nell'area in rapida evoluzione della tecnologia di elaborazione audio.
Pro e Contro
Pro
- Offre modelli di conversazione di piccole dimensioni che possono funzionare su dispositivo senza necessità di supporto cloud.
- Include modelli a singolo e doppio parlante consapevoli del contesto per applicazioni versatili.
- Utilizza un trasformatore basato su llama per la previsione dei token audio, migliorando le prestazioni.
Contro
- Il clonaggio vocale non è perfetto a causa di dati e risorse di addestramento limitati.
Domande Frequenti
vui è open source e gratuito da usare.
Secondo le nostre ultime informazioni, questo strumento non sembra avere un affare a vita al momento, purtroppo.
{toolName} offre tre modelli principali: Vui.BASE, che è il checkpoint di base addestrato su 40.000 ore di conversazioni audio; Vui.ABRAHAM, progettato come un modello a singolo parlante capace di risposte consapevoli del contesto; e Vui.COHOST, che consente la comunicazione tra due parlanti. Questi modelli servono a vari casi d'uso, che vanno dalle interazioni conversazionali fondamentali ai dialoghi complessi tra più parti.
Sì, puoi eseguire {toolName} localmente. Per installarlo, utilizza il comando pip con la seguente sintassi: 'pip install -e .'. Questo installerà lo strumento in modalità modificabile. Assicurati di avere Python installato sul tuo dispositivo per la configurazione. Segui la documentazione README nel repository per i passaggi e i requisiti dettagliati.
Sebbene {toolName} offra funzionalità di cloning vocale, è importante notare che il modello di base potrebbe non produrre risultati perfetti a causa di un dataset di addestramento limitato. Il modello non ha ricevuto un’ampia varietà di input audio, con conseguenti incoerenze nell'imitare voci specifiche. Gli utenti dovrebbero gestire le proprie aspettative e tenere presente questo aspetto quando utilizzano la funzione di cloning vocale.
{toolName} utilizza una robusta tecnica di tokenizzazione audio, sviluppata in collaborazione con Fluac, basata sul Descript-Audio-Codec. Questo riduce significativamente il numero di codici audio elaborati, diminuendo da 83,1 Hz a 21,53 Hz, consentendo una gestione dei dati più efficiente durante l'elaborazione audio. Questo miglioramento permette previsioni vocali più rapide e accurate.
Per prestazioni ottimali, {toolName} è meglio eseguito su hardware ad alte prestazioni, specificamente su configurazioni dotate di GPU NVIDIA 4090, come indicato dal suo sviluppatore. L'uso di hardware così potente riduce i tempi di elaborazione e migliora la capacità del modello di gestire operazioni audio intensive.
Sì, il {toolName} può presentare allucinazioni, in cui l'output potrebbe non corrispondere alla realtà. Questa è una sfida comune nelle prestazioni dei modelli di intelligenza artificiale, in particolare quando si addestra con risorse limitate. Gli utenti dovrebbero esserne consapevoli e verificare l'accuratezza degli output critici.
Integrare {toolName} con altri strumenti, come Whisper e Audiocraft, può espandere le sue capacità. Whisper aiuta nel riconoscimento vocale avanzato, mentre Audiocraft può migliorare le funzionalità di elaborazione audio. Esplorare queste collaborazioni può elevare significativamente l'esperienza utente e la funzionalità di {toolName}.
{toolName} è ospitato su GitHub, dove gli utenti possono trovare supporto dalla comunità attraverso segnalazioni di problemi e discussioni. Per indicazioni dettagliate sull'uso, gli utenti dovrebbero consultare la documentazione README fornita nel repository. Partecipare alla comunità può anche fornire utili consigli per la risoluzione dei problemi e intuizioni da altri utenti.