












更新情報とお得な情報をフォロー
NuExtract の割引、機能リリース、価格変更の通知を受け取る
類似のツール

NuExtract メディアギャラリー

NuExtract(レビュー)動画
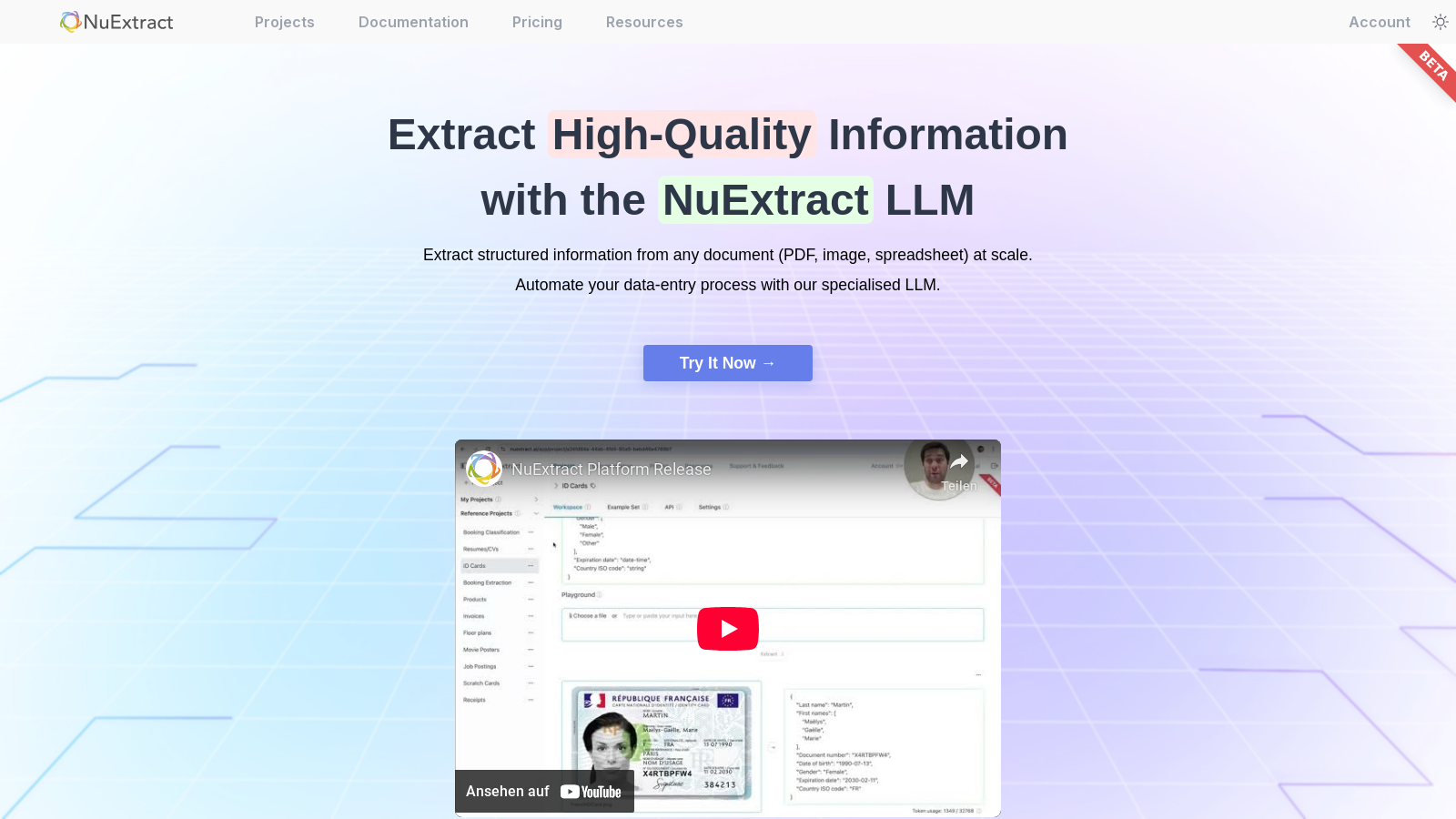
NuExtractのスクリーンショット
NuExtractとは何ですか?
NuExtractは、PDF、画像、スプレッドシートなどのさまざまなタイプのドキュメントから構造化情報を抽出することに特化した革新的なプラットフォームです。高度な大規模言語モデル(LLM)の力を活用して、NuExtractはデータ入力プロセスを自動化するだけでなく、幻想といったエラーを最小限に抑えることで精度を保証します。
パフォーマンスの利点
NuExtractの主な特徴の一つは、情報抽出タスクにおいて他の主要なLLMを上回る能力です。必要な情報を持っていない場合には自信を持って示す独自の能力によって、低い幻想率を誇っています。これは、不正確さに陥りやすい従来のモデルからの大きな飛躍を意味します。
多用途の使用ケース
NuExtractは、銀行、金融、医療、物流、マーケティング、法務など幅広い業界に対応しています。具体的な使用ケースには、請求書の解析、履歴書の分析、契約の精査などがあります。この多様性は、さまざまな分野の組織がNuExtractを活用してデータ管理プロセスを向上させることを保証します。例えば、金融機関は本人確認(KYC/KYB)や明細書の抽出を自動化し、病院は患者の受け入れや医療コーディングを効率化できます。
APIのアクセスのしやすさ
情報抽出をワークフローに組み込みたい開発者や企業のために、NuExtractは強力なAPIを提供しています。この機能により、ユーザーはドキュメントをAPIを通じて提出することでリアルタイムで情報を抽出できます。メールの解析やスキャンしたドキュメントからのデータ抽出など、APIは統合能力と運用効率を向上させます。
トークンベースの価格体系
NuExtractは、入力トークンと出力トークンの両方に適用されるミリオントークンあたりNULLを請求する競争力のある使用ベースの価格モデルを採用しています。この経済的な料金は、特に大規模な業務を行う組織がデータ抽出ニーズを拡大しながら費用を効果的に管理できるようにします。ユーザーは予想されるトークン使用に基づいて費用を予測でき、より良い財務計画を促進します。
マルチモーダル機能
このプラットフォームは、テキストと画像の両方を効果的に処理するさまざまな入力タイプをサポートしています。このマルチモーダル機能により、多様なドキュメント形式をシームレスに扱うことができ、ユーザーは元のファイルを大きく変更することなく情報を抽出できます。PDFなどのフォーマットされたドキュメントと生の画像やテキストの両方を管理できる能力は、NuExtractのユーザーフレンドリーな性質をさらに高めます。
プライベートホスティングオプション
プライバシーの重要性を理解して、NuExtractはモデルを完全にプライベートな方法で展開するオプションを提供しています。ユーザーはプライベートクラウドや自社のオンプレミスサーバーにインスタンスをホストでき、機密保持とデータセキュリティ規制への遵守を優先する組織にとって重要な機能です。このプライベートな展開では、特定の組織ニーズに合わせたモデルの微調整など、カスタマイズも可能です。
効果的なテンプレートシステム
抽出精度を最大限に高めるために、ユーザーはテンプレートを使用して抽出タスクを定義できます。これらのテンプレートは、ドキュメントから引き出す特定の情報に関する明確な指示を提供し、分析されるドキュメントの文脈に合わせてカスタマイズできます。この構造的アプローチは、出力品質を大幅に向上させます。
学習と改善
NuExtractは、ユーザー主導の学習システムを通じて継続的な改善も促進します。ユーザーは、モデルが学習できるように例を提出することでモデルの効果を高めることができ、時間と共により大きな精度をもたらすフィードバックループを作成します。各インタラクションはモデルの改善に寄与し、NuExtractは継続的な使用を通じてより正確になります。
結論
要約すると、NuExtractは多様なドキュメントタイプから高品質な情報を抽出するための包括的なソリューションです。その強力なAPI、競争力のある価格モデル、さまざまな業界への適応性により、データ処理における効率性と精度を追求する企業にとって非常に貴重なツールとなります。
利点と欠点
利点
- さまざまな文書タイプから構造化された情報を抽出するのが得意です。
- 低い幻覚率で、情報が欠如している時を正確に示します。
- 医療や金融など、さまざまな業界での広範なユースケースをサポートしています。
欠点
- トークン制約のため、20ページまでの文書処理に制限されています。
よくある質問
現在、価格情報は利用できませんので、NuExtractのウェブサイトをご確認ください。
最新の情報によると、残念ながらこのツールには現在生涯契約がないようです。
NuExtractは、生のテキスト、スキャン画像、PDF、スプレッドシート、PowerPointファイルなどの形式化されたドキュメントを含むさまざまな種類のドキュメントを処理することができます。形式化されたドキュメントを処理する際には、空間情報を保持するためにそれらを画像に変換します。この多様性により、幅広いドキュメント形式から構造化された情報を抽出することが可能です。
抽出パフォーマンスを向上させるためには、'Example Set'セクションに文書-抽出ペアの例を追加することが有効です。これにより、NuExtractは自分の誤りから学ぶことができます。また、テンプレートのフィールド名を明確に調整し、'feature fields'を含めることで、モデルを効果的に導くことができます。フォーマットされた文書の場合、ラスター化DPIを増やすか、画像の代わりにテキストバージョンを提供することで、結果を改善することも可能です。
NuExtractでプロジェクトを作成するには、まずプロジェクトバーの「+ 新しいプロジェクト」ボタンをクリックします。また、ニーズに合った既存の「リファレンスプロジェクト」を複製することもできます。プロジェクトが作成されたら、抽出するデータと出力の構造を指定するテンプレートを作成することで情報抽出タスクを定義できます。
NuExtractにおけるテンプレートは、抽出する情報と出力の整理方法を定義します。テンプレートフィールドに抽出タスクを記述し、マジックワンドアイコンを使って有効なNuExtractテンプレートを生成することで、テンプレートを作成できます。このテンプレートをさらに編集して、抽出したい内容を洗練させ、データ構造の要件に合うようにすることができます。
NuExtractは、機能にプログラム的にアクセスするためのRESTful APIを提供しています。特定のAPIエンドポイントを使用して、プロジェクトの作成、管理、および抽出タスクの実行が可能です。各プロジェクトには一意の抽出エンドポイントがあり、認証のためにAPIキーを含める必要があります。APIの使用に関する詳細なガイドや例は、ドキュメントのAPIリファレンスセクションにあります。
NuExtractが特定の文書タイプに苦しんでいる場合は、'Example Set'に修正例を追加することを検討してください。これにより、モデルがその問題に対処する方法をより正確に学習できます。また、テンプレートを分析して、モデルのために明確さやガイダンスを改善できる調整がないか確認してください。モデルにとって挑戦的な文書からの明確で多様な例を追加することで、その精度が大幅に向上する可能性があります。
はい、NuExtractプラットフォームをプライベートにデプロイすることができます。専用インスタンス、プライベートクラウド、またはオンプレミスでの展開が可能です。利点には、ドキュメントの機密性の向上、パフォーマンス向上のための抽出モデルの微調整オプション、および大量のドキュメントを処理する際の推論コストの削減の可能性が含まれます。プライベートデプロイメントについては、オプションを検討するためにNuMindに問い合わせる必要があります。
NuExtractは、その抽出APIに対して百万トークンあたりの料金を請求します。このトークンのカウントには、入力トークンと出力トークンの両方が含まれており、主にあなたのドキュメントから発生します。トークン化を理解することで、コストを効果的に見積もる手助けになるかもしれません。典型的なテキストページは約600トークンになることが多いです。また、大量のデータを処理している場合は、NuMindに相談することでトークンあたりのコストを下げるオプションがあるかもしれません。


