












NuExtract
Extract structured data from various document formats using advanced language models.
Nuextract.ai
Is this your tool?
Follow for updates & deals
Get alerts for NuExtract discounts, feature releases & pricing changes
Similar Tools
Sliq
Automated data cleaning for better data analysis.
Wayve
Automated driving solution utilizing AI for safe and adaptable navigation without reliance on HD maps.
Gretel
Generate synthetic datasets for AI applications while ensuring data privacy and compliance.
Promptfoo
Evaluate and secure large language model applications with an open-source command-line interface.
Clarify
An AI-native CRM that automates sales tasks and provides data-driven insights for effective relationship management.

NuExtract Media Gallery

NuExtract (review) video
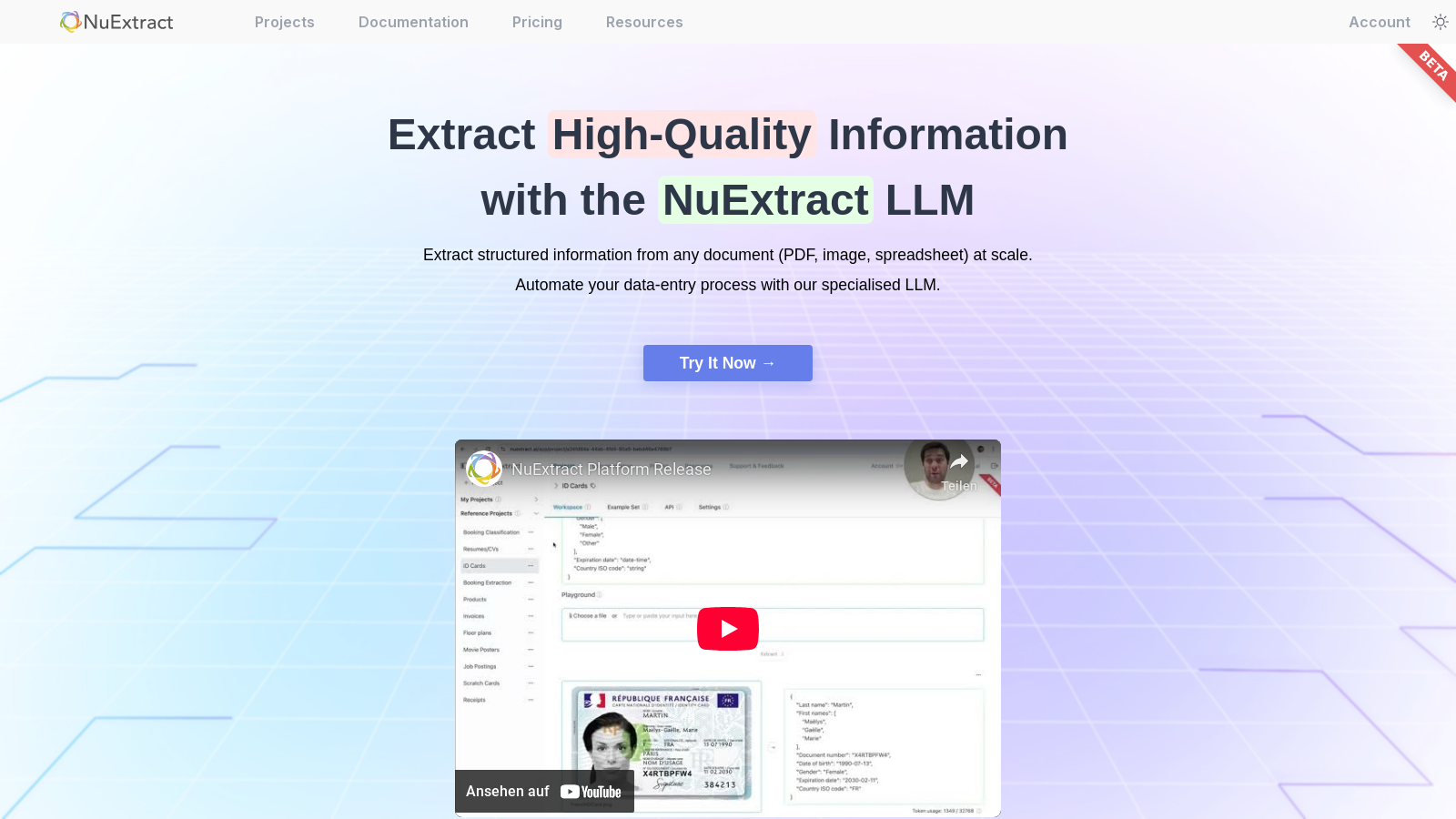
Screenshot of NuExtract
What is NuExtract?
NuExtract is an innovative platform that specializes in extracting structured information from various types of documents, including PDFs, images, and spreadsheets. With the power of advanced Large Language Models (LLMs), NuExtract not only automates the data-entry process but also ensures accuracy by minimizing errors such as hallucinations.
Performance Advantages
One of the key highlights of NuExtract is its capability to outperform other leading LLMs in information extraction tasks. It boasts a low hallucination rate, which is achieved through its unique ability to confidently indicate when it doesn't possess the required information. This represents a significant leap from traditional models often prone to inaccuracies.
Versatile Use Cases
NuExtract caters to a wide spectrum of industries including banking, finance, healthcare, logistics, marketing, and legal sectors. Specific use cases include invoice parsing, resume analysis, and contract scrutiny. This diversity ensures that organizations in various fields can leverage NuExtract to enhance their data management processes. For instance, financial institutions can automate identity verification (KYC/KYB) and statement extraction, while hospitals can streamline patient intake and medical coding.
API Accessibility
For developers and businesses looking to incorporate information extraction into their workflows, NuExtract offers a robust API. This functionality allows users to extract information in real time by submitting their documents through the API. Whether it's parsing an email or extracting data from a scanned document, the API enhances integration capabilities and operational efficiency.
Token-Based Pricing Structure
NuExtract employs a competitive usage-based pricing model charging NULL per million tokens, applicable to both input and output tokens. This economical rate allows organizations, particularly larger operations, to manage their expenses effectively while scaling their data extraction needs. Users can forecast their costs based on anticipated token usage, facilitating better financial planning.
Multimodal Capabilities
The platform supports a variety of input types, effectively processing both text and images. This multimodal capability enables seamless handling of diverse document formats, ensuring that users can extract information without needing to alter the original files significantly. The ability to manage both formatted documents like PDFs and raw images or text adds to the user-friendly nature of NuExtract.
Private Hosting Options
Understanding the importance of privacy, NuExtract provides options for deploying its models in a fully private manner. Users can host their instances on private clouds or their on-premises servers, a crucial feature for organizations prioritizing confidentiality and adherence to data security regulations. This private deployment also allows for customization, including fine-tuning of models to meet specific organizational needs.
Effective Template System
To maximize extraction accuracy, users can define extraction tasks using templates. These templates provide clear instructions regarding the specific information to be pulled from documents and can be customized to align with the context surrounding the documents being analyzed. This structured approach enhances the output quality significantly.
Learning and Improvement
NuExtract also facilitates continuous improvement through its user-guided learning system. Users have the capability to enhance the model's efficacy by submitting examples for the model to learn from, creating a feedback loop that drives greater accuracy over time. Each interaction helps the model improve, making NuExtract more precise with continued use.
Conclusion
In summary, NuExtract is a comprehensive solution for high-quality information extraction from diverse document types. Its powerful API, competitive pricing model, and adaptability across various industries make it an invaluable tool for businesses pursuing efficiency and accuracy in data handling.
Pros & Cons
Pros
- Excels at extracting structured information from diverse document types.
- Low hallucination rate, accurately indicates when information is absent.
- Supports extensive use cases across various industries like healthcare and finance.
Cons
- Limited to processing documents up to 20 pages due to token constraints.
Frequently Asked Questions
We have no pricing information available now, so please check the NuExtract's website.
According to our latest information, this tool does not seem to have a lifetime deal at the moment, unfortunately.
NuExtract is capable of processing various types of documents, including raw text, scanned images, and formatted documents like PDFs, spreadsheets, and PowerPoint files. When processing formatted documents, they are converted to images to maintain spatial information. This versatility allows you to extract structured information from a wide range of document formats.
To enhance extraction performance, you can add examples of document-extraction pairs in the 'Example Set' section, which helps NuExtract learn from its mistakes. Additionally, tweaking the template field names for clarity and including 'feature fields' can guide the model effectively. For formatted documents, increasing the rasterization DPI or providing text versions instead of images can also help improve results.
To create a project in NuExtract, start by clicking the '+ New project' button in the project bar. You can also duplicate an existing 'Reference Project' that aligns with your needs. Once your project is created, you can define the information extraction task by building a template that specifies what data to extract and how to structure the output.
The template in NuExtract defines what information to extract and how to organize the output. You can create a template by describing the extraction task in the template field and then using the magic wand icon to generate a valid NuExtract template. You can further edit this template to refine what you want to extract, ensuring it aligns with your data structure requirements.
NuExtract provides a RESTful API to access its features programmatically. You can create, manage projects, and execute extraction tasks using specific API endpoints. Each project has a unique extraction endpoint, and you need to include your API key for authentication. Detailed guides and examples for using the API are available in the API Reference section of the documentation.
If NuExtract struggles with certain document types, consider adding correction examples to the 'Example Set,' which helps train the model on how to handle those issues more accurately. You should also analyze your template to see if there are adjustments you can make to improve clarity or guidance for the model. Adding clear and varied examples from documents that challenge the model can significantly improve its accuracy.
Yes, you can deploy the NuExtract platform privately, either on a dedicated instance, private cloud, or on-premises. Benefits include enhanced confidentiality for your documents, the option to fine-tune the extraction model for improved performance, and potentially lower inference costs when processing a large volume of documents. For private deployment, you would need to contact NuMind to discuss options.
NuExtract charges? Per million tokens for its extraction API. This token count includes both input and output tokens, with the majority coming from your documents. Understanding tokenization may help you estimate costs effectively, as the typical page of text can average around 600 tokens. If you're processing large volumes, you may have options to lower the cost per token by discussing your needs with NuMind.


